- Capabilities
- Getting started
- Architecture center
- Platform updates
Media
Foundry enacts strict memory limits when executing TypeScript v1 functions. To ensure you do not exceed those memory limits, you should only interact with media files under 20MB.
Functions enable you to access and modify media using TypeScript v1, TypeScript v2, and Python. TypeScript v1 functions provide a MediaItem type that exposes a number of methods for conveniently interacting with the underlying media, with built-in operations that allow you to easily interact with different kinds of media without external libraries. TypeScript v2 and Python support media uploads through Ontology edits.
If you need any operations that don't currently exist out-of-the-box, you will likely need to use external libraries or write your own custom code. Learn more about adding dependencies to functions repositories.
Upload media in Ontology edit functions
You cannot pass uploaded media into a query function within the same uploaded function.
Uploading media within a function is not supported in TypeScript v1.
Use Ontology edit functions to upload media and create objects in the Ontology. Once uploaded, you can read and download media files from objects for use in your application. Learn more about media sets in Foundry.
You can construct Ontology edits in TypeScript v2 and Python functions using media types by uploading media to the Ontology to obtain a MediaReference. While you can use the MediaReference to construct an Ontology edit, you can also do so by passing existing media into the function parameter.
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13import { OntologyEditFunction, MediaItem } from "@foundry/functions-api"; import { Aircraft } from "@foundry/ontology-api"; export class MyFunctions { @OntologyEditFunction() public async setExistingMediaToObject( aircraft: Aircraft, mediaItem: MediaItem ): Promise<void> { // Ontology Edits with passed in MediaItems are supported aircraft.myMediaProperty = mediaItem; } }
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20// Ensure you are using TypeScript OSDK 2.6 or greater to use media uploads // in Ontology Edit Functions. import type { Client } from "@osdk/client"; import { Aircraft } from "@ontology-sdk/sdk"; import type { Edits } from "@osdk/functions"; import { createEditBatch, uploadMedia } from "@osdk/functions"; async function uploadTextToNewPlane(client: Client): Promise<Edits.Object<Aircraft>[]> { const batch = createEditBatch<Edits.Object<Aircraft>>(client); const blob = new Blob(["Hello, world"], { type: "text/plain" }); const mediaReference = await uploadMedia( client, { data: blob, fileName: "/planes/aircraft.txt" } ); batch.create(Aircraft, { myMediaProperty: mediaReference, /* ... */ }); return batch.getEdits(); } export default uploadTextToNewPlane;
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21# Ensure you are using Python OSDK 2.145 or greater to use media uploads # in Ontology Edit Functions. from ontology_sdk import FoundryClient from ontology_sdk.ontology.objects import Aircraft from functions.api import function, OntologyEdit @function(beta=True, edits=[Aircraft]) def upload_text_to_new_plane() -> list[OntologyEdit]: client = FoundryClient() edits = client.ontology.edits() media_reference = client.ontology.media.upload_media( body="Hello, world".encode("utf8"), filename="/planes/aircraft.txt", ) edits.objects.Aircraft.create( pk = "primary_key", my_media_property=media_reference, # ... ) return edits.get_edits()
Media item parameter
There are two ways to interact with media items in functions:
- Using a media property on an object type
- Passing a media reference parameter of an action type to the function
Using media property of an object type
The following example shows the isAudio media operations on a media reference property of an object type.
Copied!1MediaItem.isAudio(objectType.mediaReferenceProperty)
Passing a media reference parameter on action type
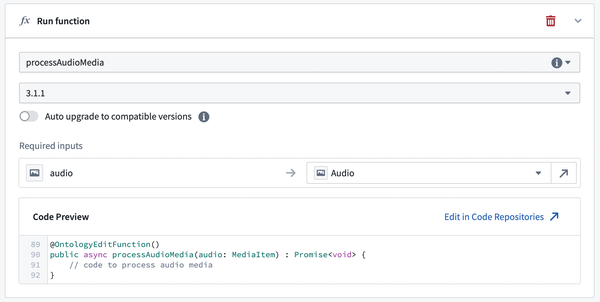
Action parameters of type media reference can be passed to the function as a parameter.
The screenshot below shows an action passing a media parameter to its backing function.
Universal operations
The universal operations outlined below are currently not available for the TypeScript v2 and Python MediaReference type. However, they are available for the TypeScript v2 and Python Media type, which is a property on an object type.
Some operations are supported by all media types.
Read raw media data
You can access a media item by selecting the media reference property on the object. The signature for the method is as follows:
Copied!1 2 3// Blob is a standard JavaScript type, representing a file-like object of immutable, raw data. // https://developer.mozilla.org/en-US/docs/Web/API/Blob readAsync(): Promise<Blob>;
Copied!1 2 3 4 5 6 7 8 9 10 11fetchContents(): Promise<Response>; // Example usage: const mediaContents = await myAircraft.myMediaProperty.fetchContents(); if (mediaContents.ok) { const mediaMimeType = mediaContents.headers.get("Content-Type"); // Blob is a standard JavaScript type, representing a file-like object of immutable, raw data. // https://developer.mozilla.org/en-US/docs/Web/API/Blob const mediaBlob: Blob = mediaContents.blob(); }
Copied!1 2 3 4 5 6from io import BytesIO get_media_content(self) -> BytesIO: ... # Example usage: raw_data: BytesIO = my_aircraft.my_media_property.get_media_content()
Get media metadata
You can access a media item's metadata. The signature for the method is as follows:
Copied!1getMetadataAsync(): Promise<IMediaMetadata>;
Copied!1 2 3 4 5 6fetchMetadata(): Promise<MediaMetadata>; // Example usage: const mediaMetadata = await myAircraft.myMediaProperty.fetchMetadata(); const sizeBytes = mediaMetadata.sizeBytes; const mediaType = mediaMetadata.mediaType;
Copied!1 2 3 4 5 6 7 8from foundry_sdk.v2.ontologies.models import MediaMetadata get_media_metadata(self) -> MediaMetadata: # Example usage: media_metadata: MediaMetadata = my_aircraft.my_media_property.get_media_metadata() size_bytes = media_metadata.size_bytes media_type = media_metadata.media_type
Type guards in TypeScript v1
Type guards in TypeScript v1 allow you to access functionality that is specific to certain media types. The following type guards can be used on media item metadata:
isAudioMetadata()isDicomMetadata()isDocumentMetadata()isImageryMetadata()isSpreadsheetMetadata()isUntypedMetadata()isVideoMetadata()
As an example, you could use the imagery type guard to pull out image specific metadata fields:
Copied!1 2 3 4 5const metadata = await myObject.mediaReference?.getMetadataAsync(); if (isImageryMetadata(metadata)) { const imageWidth = metadata.dimensions?.width; ... }
You can also use type guards on the media item namespace, which then gives you access to more methods on the type-specific media item. The type guards you can use here are:
MediaItem.isAudio()MediaItem.isDicom()MediaItem.isDocument()MediaItem.isImagery()MediaItem.isSpreadsheet()MediaItem.isVideo()
Document-specific operations
Document-specific operations are not currently available in TypeScript v2 and Python functions.
Text extraction
To extract text from a document, you can either use optical character recognition (OCR) or extract embedded text on the media item.
For machine-generated PDFs, it may be faster and/or more accurate to extract text embedded digitally in the PDF rather than using optical character recognition (OCR). Below is an example of text extraction usage:
Copied!1extractTextAsync(options: IDocumentExtractTextOptions): Promise<string[]>;
When using TypeScript v1, the following can optionally be provided as an object:
startPage: The zero-indexed start page (inclusive).endPage: The zero-indexed end page (exclusive).
For non-machine-generated PDFs, it would be best to use the OCR method for extracting text.
Copied!1ocrAsync(options: IDocumentOcrOptions): Promise<string[]>;
The following can optionally be provided as a TypeScript object:
startPage: The zero-indexed start page (inclusive).endPage: The zero-indexed end page (exclusive).languages: A list of languages to recognize (can be empty).scripts: A list of scripts to recognize (can be empty).outputType: Specifies the output type astextorhocr.
Remember that you need to use type guards in order to access media-type specific operations. Here's an example of using the isDocument() type guard to then perform OCR text extraction:
Copied!1 2 3 4 5 6 7 8 9 10 11 12import { MediaItem } from "@foundry/functions-api"; import { ArxivPaper } from "@foundry/ontology-api"; @Function() public async firstPageText(paper: ArxivPaper): Promise<string | undefined> { if (MediaItem.isDocument(paper.mediaReference)) { const text = (await paper.mediaReference.ocrAsync({ endPage: 1, languages: [], scripts: [], outputType: 'text' }))[0]; return text; } return undefined; }
Audio-specific operations
Audio-specific operations are not currently available in TypeScript v2 and Python functions.
Transcription
Audio media items support transcription using the transcribe method. The signature is as follows:
Copied!1transcribeAsync(options: IAudioTranscriptionOptions): Promise<string>;
The following can optionally be passed in to specify how the transcription should run. The available options are:
language: The language to transcribe, passed using theTranscriptionLanguageenum.performanceMode: Runs transcriptions inMore EconomicalorMore Performantmode, passed using theTranscriptionPerformanceModeenum.outputFormat: Specifies the output format by passing an object oftypeplainTextNoSegmentData(plain text) orpttml.pttmlis a TTML-like ↗ format where the object also takes a booleanaddTimestampsparameter if the type isplainTextNoSegmentData.
Here's an example of providing options for transcription:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15import { Function, MediaItem, TranscriptionLanguage, TranscriptionPerformanceMode } from "@foundry/functions-api"; import { AudioFile } from "@foundry/ontology-api"; @Function() public async transcribeAudioFile(file: AudioFile): Promise<string|undefined> { if (MediaItem.isAudio(file.mediaReference)) { return await file.mediaReference.transcribeAsync({ language: TranscriptionLanguage.ENGLISH, performanceMode: TranscriptionPerformanceMode.MORE_ECONOMICAL, outputFormat: {type: "plainTextNoSegmentData", addTimestamps: true} }); } return undefined; }