- Capabilities
- Getting started
- Architecture center
- Platform updates
AIP Document Intelligence
AIP Document Intelligence is Foundry's entry point for all document extraction workflows. You can use AIP Document Intelligence to open a media set of enterprise documents, quickly execute different state-of-the-art document extraction strategies, and retrieve evaluation results of the quality, speed, and token cost of such strategies. With a single click, you can then deploy the configured extraction strategy as a Python transform to a batch pipeline over a media set.
Features
AIP Document Intelligence features several extraction capabilities alongside a simplified interface for efficient walk-up use:
- Intuitive user interface: Easily search for and select Foundry media sets to process with a variety of extraction strategies.
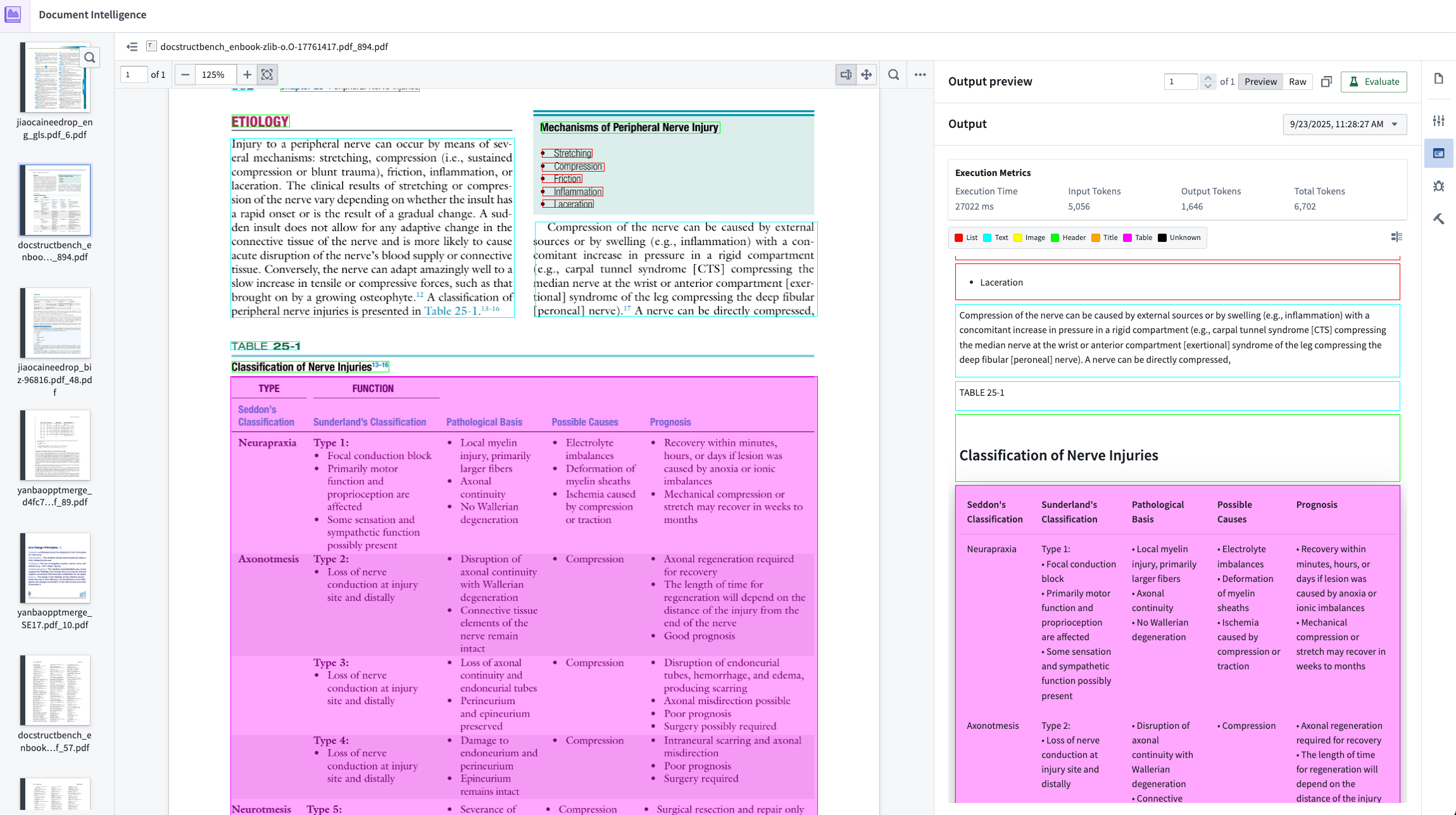
- Quick confirmation loop: Results of an executed strategy are easy to confirm using the Markdown output mapped to bounding boxes on the original PDF.
- Traditional extractions: Leverage preexisting strategies to extract Markdown from the document:
- Raw text: Extracts text by reading document metadata. Only available for electronically generated PDFs.
- OCR: Uses traditional OCR (Optical Character Recognition) to extract text without preserving layout information.
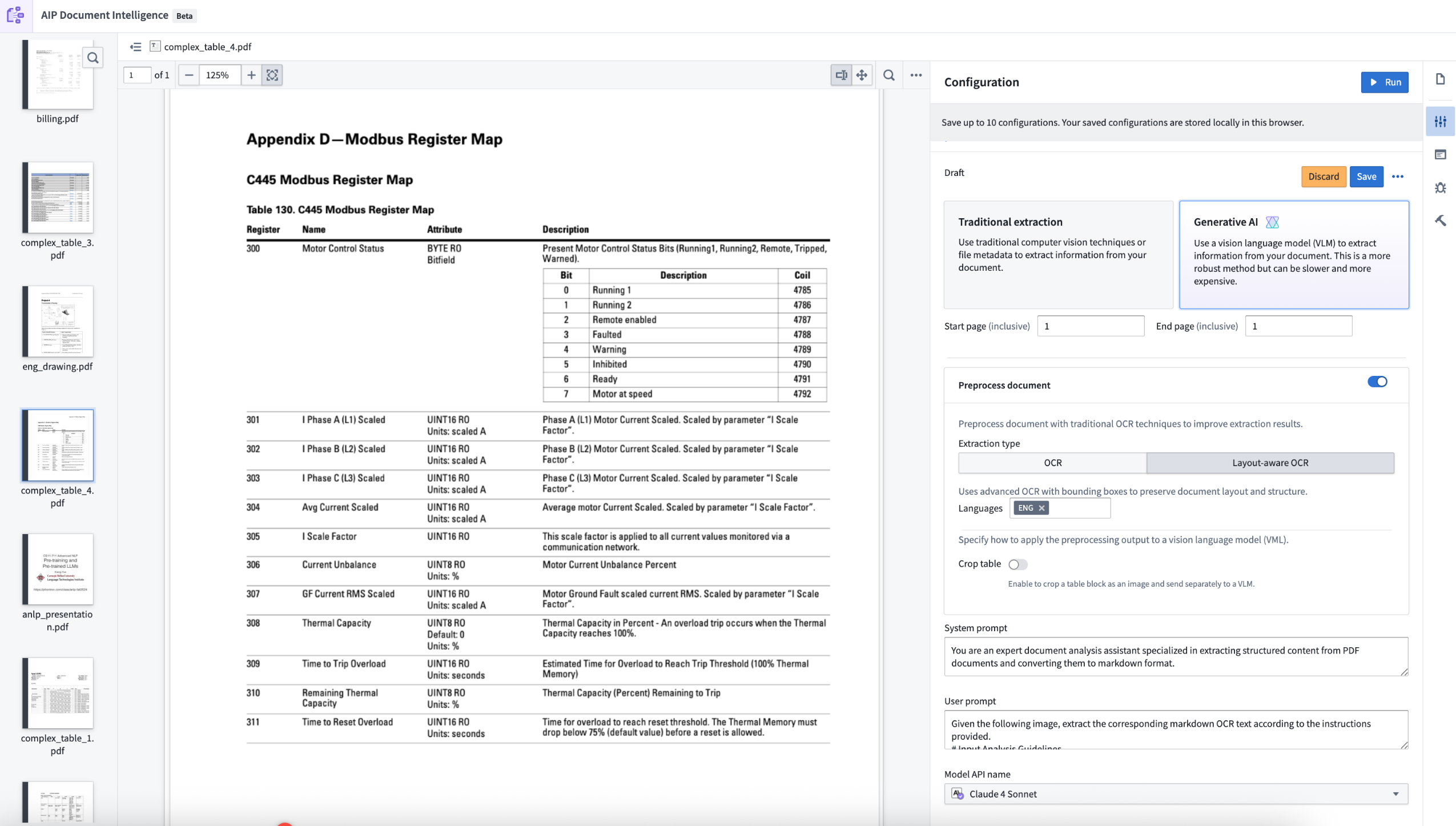
- Layout-aware OCR: Uses advanced OCR with bounding boxes to preserve document layout and structure.
- Generative AI extractions: Execute vision language model (VLM) strategies with prompts that are fine-tuned to extract Markdown. The default prompts are tuned to yield best performance in our internal evaluation set. You can also modify the prompts with custom logic through the configuration interface.
- Preprocessing with VLM extractions: For more complex use cases, you can combine document preprocessing with traditional methods, such as layout-aware OCR. Then, you can pass the results of the preprocessing to a VLM for better performance. Learn more about document preprocessing.
- Execution metrics: Observe rubric metrics for extraction quality, execution time, and input/output token consumption.
- Evaluations: Using the VLM as a judge, extraction results are scored on a variety of factors that may be included in the document, including the quality of lists, tables, and code blocks. The evaluation strategy is tuned to match evaluation results against ground truth in our internal evaluation set. Learn more about extraction evalutions.
- Deployment: After confirming an ideal extraction strategy, easily deploy the strategy into a Python transforms repository with a single click. The transforms will be configured with the exact extraction strategy, including model selection and any prompt modifications. Learn more about extraction strategy deployment.
Getting started
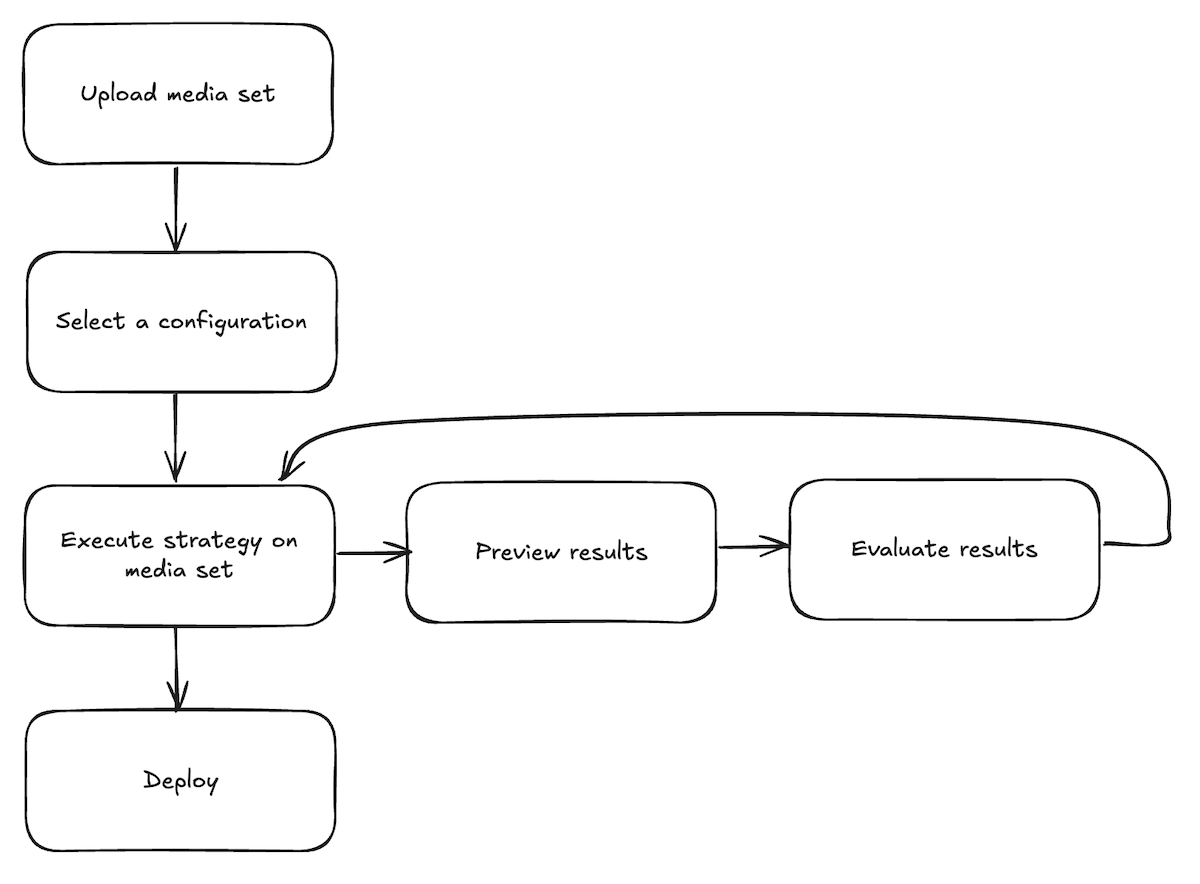
AIP Document Intelligence follows a testing workflow where users import a media set, select a configuration, and iterate on their strategy by observing results and evaluations until satisfaction before deploying. Follow the steps below to get started:
-
Upload a media set: From the application landing page, choose to select a media set from your available files, or upload a new media set.
-
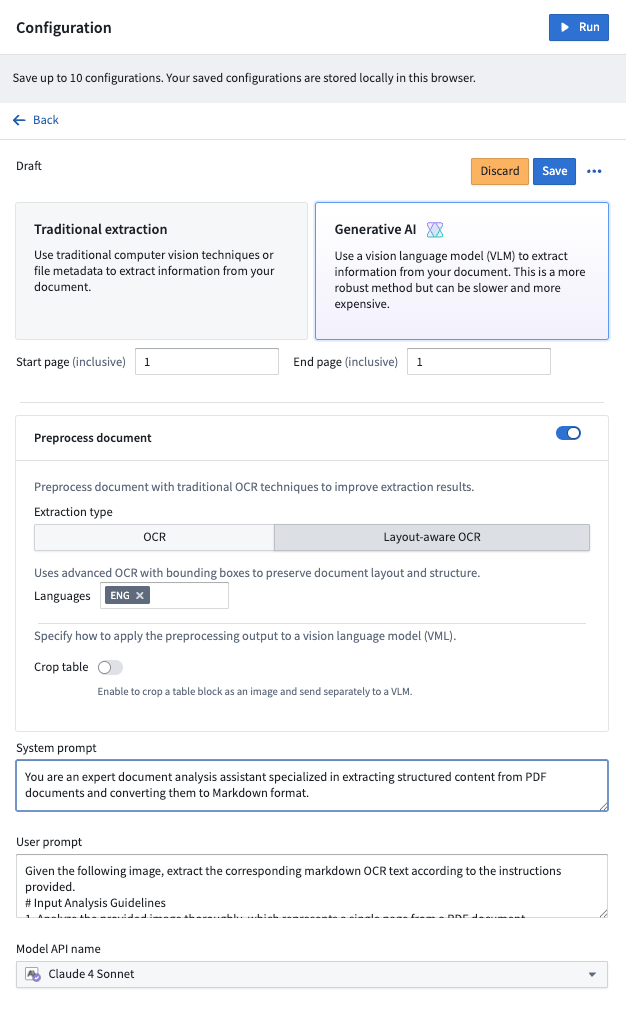
Select a configuration: Once the media set opens, open the Configuration tab to set up the extraction method you want to use. Choose between traditional or generative AI methods, enable preprocessing if desired, and customize prompts to use with a VLM. Select Save to remember your configuration choice in the future.
-
Execute strategy on a media set: After configuring the extraction method, select Run in the top right corner of the Configuration tab.
-
Preview extraction results: After running the extraction, navigate to the Extraction result tab to view the output based on the chosen strategy.
-
Evaluate extraction results (optional): From the results tab, select Evaluate results to use an LLM to evaluate the extraction results. Continue to test steps 3 through 5 until you are satisfied with the extraction results and evaluation.

-
Visualize chunking (optional): From the Extraction result tab, select the Chunk button next to an extraction result to preview how text will be split. You can adjust chunking parameters and see the results.
-
Deploy extraction strategy: Open the Deployment tab, select your saved configuration from the dropdown menu, and select Create transform repository. You will be prompted to choose a name and location for a new Python transforms repository. Optionally enable chunking and embedding. After the repository is created, specify the output dataset and start the build. See the repository's
README.mdfor detailed instructions.