- Capabilities
- Getting started
- Architecture center
- Platform updates
Iceberg tables [Beta]
Iceberg table support is in the beta phase of development and may not be available on your enrollment. Functionality may change during active development. Contact Palantir Support to request enabling Iceberg tables.
Apache Iceberg ↗ is a widely adopted open-source table format and is available in Foundry via Iceberg tables as an alternative resource type for representing tabular data.
Foundry offers Iceberg both as managed tables and as virtual tables via an external catalog or storage provider.
What is Iceberg?
Apache Iceberg ↗ is an open table format that has gained significant traction in the data and analytics community due to benefits around scalability, performance, and broad ecosystem support. In particular, the wide adoption of the Iceberg format specification enables a broad array of integrations and interoperability across modern data ecosystems.
The Apache Iceberg project includes the Apache Iceberg table format specification ↗, as well as a set of engine connectors that support the Iceberg specification, such as Spark ↗, Flink ↗ and more.
Beyond the core Apache Iceberg project, there is a growing ecosystem of connectors and engines that support the Iceberg format:
- PyIceberg ↗ provides a gateway into the Python ecosystem.
- Engines like Trino ↗ and PrestoDB ↗ offer native support.
- Other third-party tools and platforms, such as Databricks ↗ and Snowflake ↗, provide offerings built on top of the Iceberg format.
Foundry Iceberg catalog
Apache Iceberg defines an Iceberg REST Catalog ↗ specification, which outlines a set of endpoints and behaviors that a service must implement to function as an Iceberg REST catalog.
By adhering to this specification, the service becomes compatible with a growing number of compute engines that support the Iceberg REST Catalog.
Foundry now natively implements this Iceberg REST Catalog specification, In addition, Foundry also supports connectivity to third-party Iceberg REST catalogs such as Databricks Unity Catalog ↗. See Virtual tables: Iceberg catalogs for supported third-party catalogs.
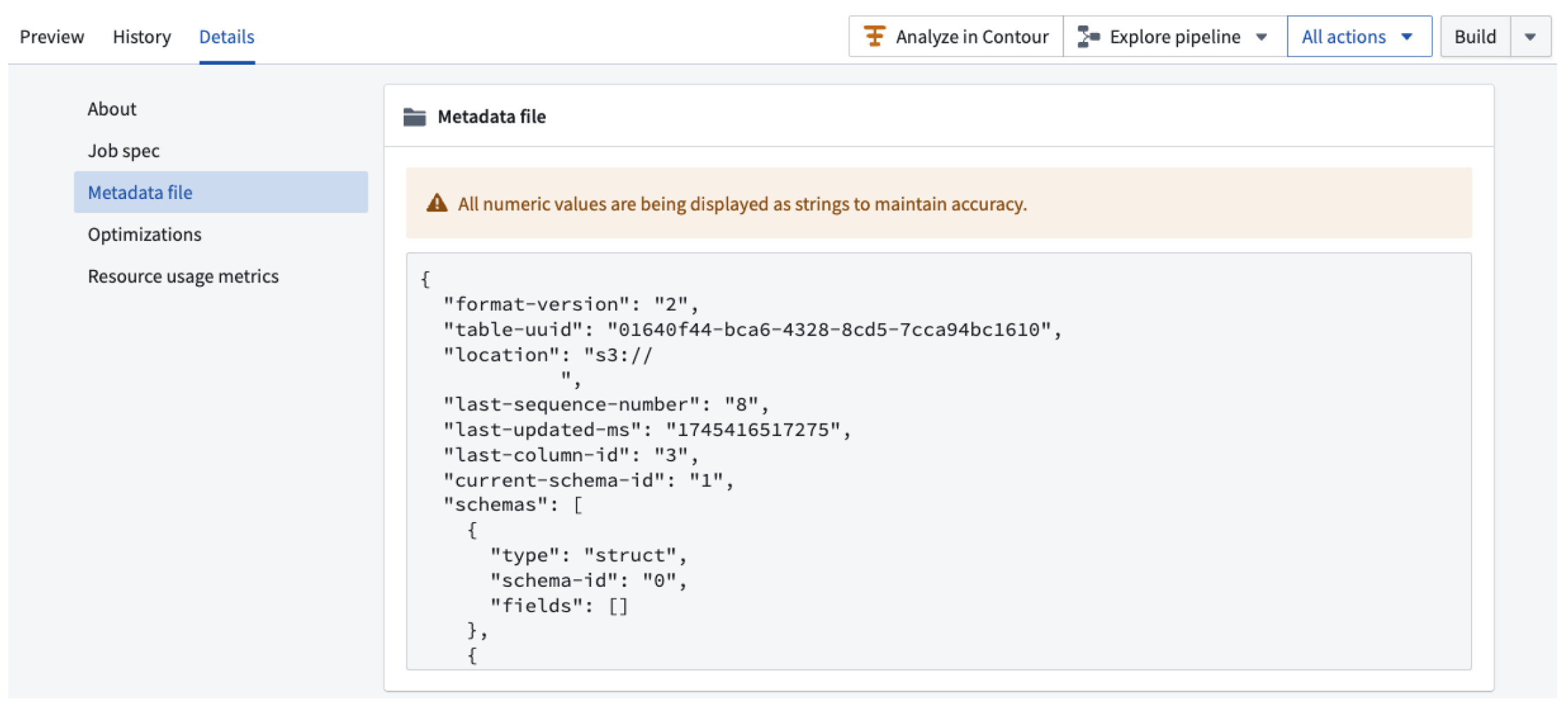
Foundry exposes Iceberg catalog metadata explicitly as a JSON file via dataset application under the Details tab.
The screenshot below shows how Iceberg catalog metadata appears in the dataset application:
Iceberg tables vs. datasets
As Palantir expands coverage for Iceberg tables, the features and benefits available for Foundry Iceberg tables will grow over time and limitations will be removed.
Below summarizes the current state of support as compared to datasets, while Iceberg tables are in the Beta phase of development.
Benefits of Iceberg tables
The following benefits of Iceberg tables are currently available in Foundry:
- Interoperability: Open Iceberg format means third-party tools can more easily read and write Palantir Iceberg tables.
- Compaction: Support for automated compaction without affecting incremental reads.
- Row edits: Support for
DELETE,UPDATEandMERGE INTOstatements, which allow you to conditionally modify rows without the need to re-snapshot. - Changelogs: Incrementally consume row deletions and updates.
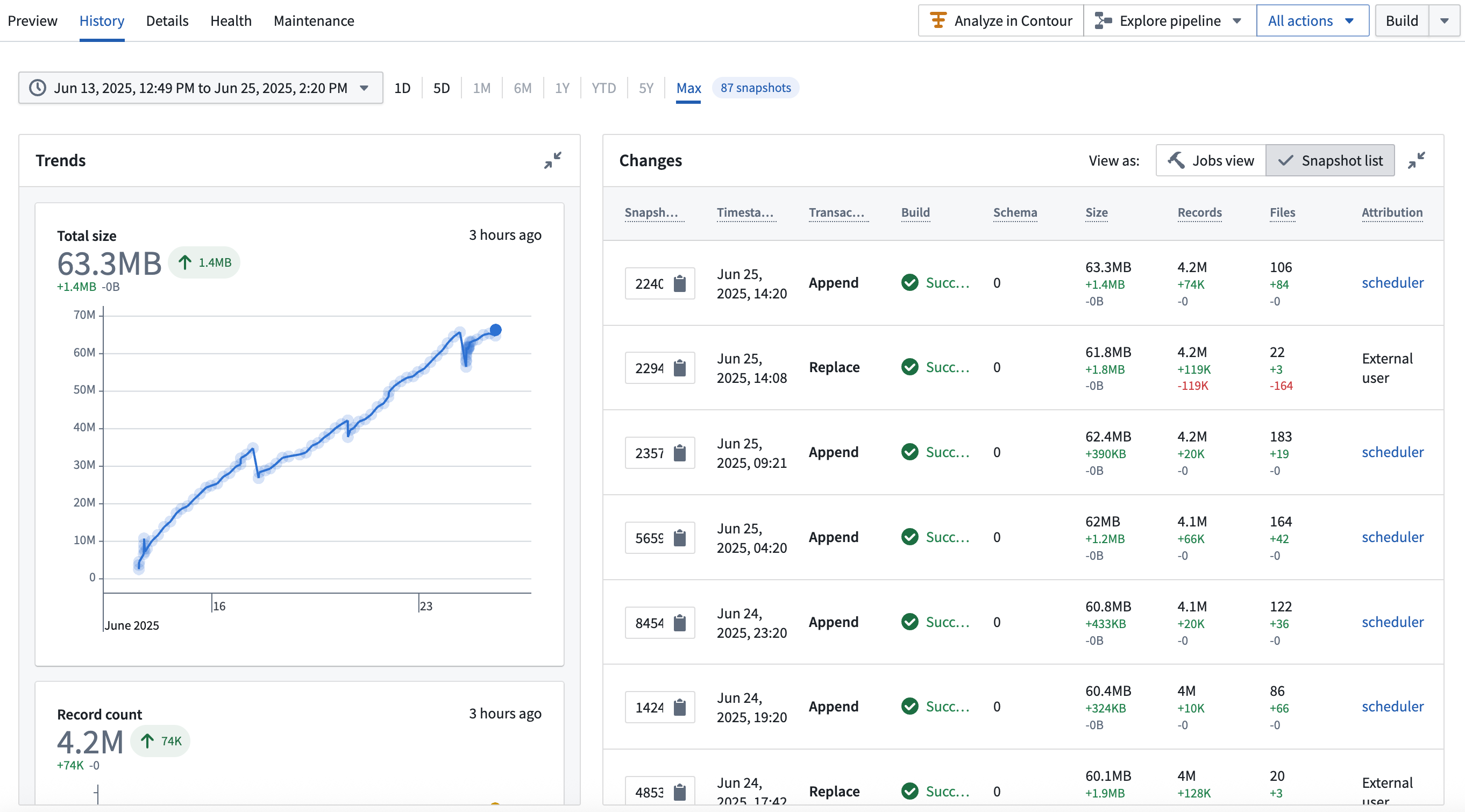
- Enriched table history: Enhanced history view surfacing Iceberg table metadata ↗.
The interface for viewing Iceberg table history can be seen in the following screenshot:
Notable differences between Iceberg tables and Foundry datasets
There are several notable differences worth calling out between the behavior of Iceberg tables and Foundry datasets today. Note that Palantir is exploring features to improve consistency on these dimensions and working towards parity across the two formats.
- Default branches: Iceberg’s main branch is called
main, whereas Foundry’s main branch is calledmaster. In Foundry’s integration with Iceberg,mainandmasterare treated as the same, which means a Foundry job running onmasterwill write to an Iceberg’s table'smain. - Schema evolution on branches: In Iceberg, branches do not have their own schemas. Instead, branches track the "current" schema and the current schema is shared across a table by all branches. This means that you cannot alter the schema on a branch without also changing the schema on
main. - Automatic schema evolution: Iceberg is strict about the schema when writing to an existing Iceberg table. Any change in schema needs to be made explicitly via an
ALTER TABLEcommand.
Foundry functionality not yet available for Iceberg tables
Note that certain Foundry features are not currently supported for Iceberg tables, including:
- Views (Foundry views and Iceberg views ↗)
- Restricted views
- Streaming
- Timeseries syncs
- Projections
- Faster pipelines in Pipeline Builder
Iceberg terminology disambiguation
Iceberg introduces terms that do not always have direct equivalents in Foundry:
| Iceberg term | Meaning | Foundry disambiguation |
|---|---|---|
| Table metadata ↗ | Metadata describing the structure, schema, and state of an Iceberg table. | Foundry also tracks metadata for tables and datasets across all formats, but this metadata is managed internally by Foundry services. For Iceberg tables, Foundry exposes the native Iceberg metadata explicitly as a JSON file via the Iceberg catalog. |
| Snapshots ↗ | A record of the table's state at a specific point in time. Iceberg creates a new snapshot with every data modification. | An Iceberg snapshot is roughly equivalent to a Foundry transaction. However, Foundry also uses the term "snapshot" differently: in Foundry, a "snapshot" refers to a transaction that fully replaces all data in a dataset, while an Iceberg snapshot captures all types of data operations, including incremental changes. See Iceberg snapshot types for a complete disambiguation of Foundry catalog dataset transaction types and Iceberg snapshot types. |
Using Iceberg in Foundry
Refer to the Iceberg tables section of the documentation for details and guides on working with Foundry Iceberg tables.