- Capabilities
- Getting started
- Architecture center
- Platform updates
Virtual tables
Virtual tables allow you to query tables in supported data platforms without first storing the data in a Foundry dataset.
A virtual table acts as a pointer to a table in a source system outside of Foundry. Virtual tables abstract away the underlying source system and storage formats, enabling you to build workflows that combine data from different source systems seamlessly. Virtual tables can also be combined with datasets stored in Foundry as part of a flexible architecture where data need not be consolidated in one place. You can also create new virtual tables as outputs from Foundry data transformations, enabling workflows where storage is fully external and Foundry handles orchestration, security, and other functions.

A virtual table is defined by:
- A connection to the source storage system (for example, a source URL or credentials). This connection is established by setting up a source in Foundry's data connection application.
- A locator which identifies the table in the source system (for example, the database, schema, and table name).
As with any resource in Foundry, virtual tables are governed by Foundry's security and permissions model and can be opened or used in various Foundry applications.
Supported sources
The following sources support virtual tables. Refer to the source documentation for more details on how to configure the connection as well as the supported capabilities.
| Source | Status | Supported Formats | Manual Registration | Automatic Registration |
|---|---|---|---|---|
| Amazon S3 | 🟢 Generally available | Avro ↗, Delta ↗, Iceberg ↗, Parquet ↗ | ✔️ | |
| OneLake and Azure Data Lake Storage Gen2 (Azure Blob Storage) | 🟢 Generally available | Avro ↗, Delta ↗, Iceberg ↗, Parquet ↗ | ✔️ | |
| BigQuery | 🟢 Generally available | Table, View, Materialized View | ✔️ | ✔️ |
| Databricks | 🟢 Generally available | Table, View, Materialized View | ✔️ | ✔️ |
| Foundry | 🟡 Beta | Only managed Iceberg | ✔️ | |
| Google Cloud Storage | 🟢 Generally available | Avro ↗, Delta ↗, Iceberg ↗, Parquet ↗ | ✔️ | |
| Snowflake | 🟢 Generally available | Table, View, Materialized View | ✔️ | ✔️ |
Iceberg catalogs
An Iceberg catalog is required to load virtual tables backed by an Apache Iceberg table. To learn more about Iceberg catalogs, see the Apache Iceberg documentation ↗. Virtual tables support different catalogs depending on the source being used. The table below highlights the supported catalogs. Refer to the source documentation for more details on how to configure each catalog and use Iceberg tables from the source.
| Source | AWS Glue | Horizon Catalog | Object Storage | Polaris | Unity Catalog |
|---|---|---|---|---|---|
| Amazon S3 | 🟢 Generally available | 🔴 Not available | 🟢 Generally available | 🟢 Generally available | 🟡 Legacy: recommended to use Databricks source. |
| Databricks | - | - | - | - | 🟢 Generally available |
| Google Cloud Storage | 🔴 Not available | 🔴 Not available | 🟢 Generally available | 🔴 Not available | 🔴 Not available |
| OneLake and Azure Data Lake Storage Gen2 (Azure Blob Storage) | 🔴 Not available | 🔴 Not available | 🟢 Generally available | 🟢 Generally available | 🟡 Legacy: recommended to use Databricks source. |
| Snowflake | - | 🟢 Generally available | - | - | - |
Supported Foundry workflows
Virtual tables are supported as inputs in the below applications and workflows, and as outputs in Pipeline Builder and Code Repositories.
| Supported application | Supported workflow | Not supported |
|---|---|---|
| Data Connection | Configure source Register virtual tables | Agent-based connections |
| Contour | Analyze in Contour | Save as dataset |
| Ontology | Object creation via Ontology Manager [Beta] Object creation via Pipeline Builder | |
| Data Lineage | View Foundry lineage | |
| Pipeline Builder | Pipeline input Pipeline output [Beta] Snapshot builds Incremental builds (append-only) External pipeline (compute pushdown) [Beta] | Streaming builds Faster pipelines |
| Code Repositories | Python Transforms Java Transforms SQL Transforms Snapshot builds Incremental builds (append-only) Compute pushdown |
Note that some source types may not support all these capabilities. Refer to the source-specific documentation for more details. Learn more about how to configure a source when using virtual tables in Code Repositories.
In general, virtual tables can be used to back most common Foundry workflows by either:
- Directly interacting with the virtual table as described above, or
- Creating a transformation pipeline backed by a virtual table that outputs Foundry datasets or objects. These outputs can be used as normal in the platform.
Virtual table compatibility matrix by source & table type
The matrix below provides an overview of the key capabilities available for virtual tables, broken down by data source and table type. For full details, including any source-specific limitations or advanced features, refer to the source-specific documentation.
| Source | Table type | Capability | Foundry compute | Compute pushdown* |
|---|---|---|---|---|
| BigQuery | Tables, Views, Materialized Views, Other | ✅ Read ✅ Write | ✅ Python: Single-node ✅ Python: Spark ❌ Pipeline Builder: Single-node ✅ Pipeline Builder: Spark | ✅ Python (Ibis) ❌ Pipeline Builder |
| Databricks | External Delta, Managed Iceberg | ✅ Read ✅ Write | ✅ Python: Single-node ✅ Python: Spark ❌ Pipeline Builder: Single-node ✅ Pipeline Builder: Spark | ✅ Python (PySpark) ✅ Pipeline Builder |
| Databricks | Managed Delta | ✅ Read ❌ Write | ✅ Python: Single-node ✅ Python: Spark ❌ Pipeline Builder: Single-node ✅ Pipeline Builder: Spark | ✅ Python (PySpark) ✅ Pipeline Builder |
| Databricks | Views, Materialized Views, Other | ✅ Read ❌ Write | ✅ Python: Single-node ✅ Python: Spark ❌ Pipeline Builder: Single-node ✅ Pipeline Builder: Spark | ✅ Python (PySpark) ✅ Pipeline Builder |
| Snowflake | Tables, Views, Materialized Views, Other | ✅ Read ✅ Write | ✅ Python: Single-node ✅ Python: Spark ❌ Pipeline Builder: Single-node ✅ Pipeline Builder: Spark | ✅ Python (Snowpark) ✅ Pipeline Builder |
| Snowflake | Managed Iceberg | ✅ Read ❌ Write | ❌ Python: Single-node ✅ Python: Spark ❌ Pipeline Builder: Single-node ✅ Pipeline Builder: Spark | ✅ Python (Snowpark) ✅ Pipeline Builder |
| AWS S3 | Parquet, Avro, CSV, Delta | ✅ Read ✅ Write | ❌ Python ❌ Pipeline Builder | NA |
| Azure ADLS | Parquet, Avro, CSV, Delta | ✅ Read ✅ Write | ❌ Python ❌ Pipeline Builder | NA |
| Google Cloud Storage | Parquet, Avro, CSV, Delta | ✅ Read ✅ Write | ❌ Python ❌ Pipeline Builder | NA |
* Compute pushdown refers to using the native compute engine of the source system.
Set up a connection for a virtual table
Sources supporting virtual tables are set up in the Data Connection application. Select the source that you want to use, then navigate to the Virtual tables tab in the source configuration. Follow the source-documentation and any requirements listed there for using virtual tables.

Create virtual tables
All supported sources allow you register individual tables from the source system in Foundry. Tabular source types also support bulk registration of multiple virtual tables at once. Some sources additionally support automatic registration, which will periodically register all tables in the source that are accessible to the configured credentials in a designated project.
To register a virtual table, select Create virtual table in the Virtual tables tab in the source. Browse available tables and select the table to register. Unless you choose a different location, the virtual table will be created in the default output folder of the source.

Bulk registration
When working with tabular source types such as Databricks, BigQuery, and Snowflake, you will be able to bulk register multiple virtual tables at once. To begin, select one or more external tables from the left panel. Use the right panel to change where your new virtual tables will be saved, or update their names. Note that changing the name of a virtual table in Foundry does not change the table name in the source.

Auto-registration
When enabling auto-registration, you create a new Foundry project where virtual tables will be created automatically. The folder hierarchy in this project will mirror the structure of the source system, and be periodically updated as new tables are created in the source. When source tables are deleted, related virtual tables won't be auto-deleted in the project, but accessing them won't load any data.
To enable auto-registration, you must have project creation permissions in Foundry.

The project is managed by Foundry, and users cannot manually create or update resources in it. Virtual tables registered in this project can be imported into other projects for use in workflow development.
Enabling auto-registration allows setting permissions and access to the project, which can later be managed by the project owner using the access sidebar.

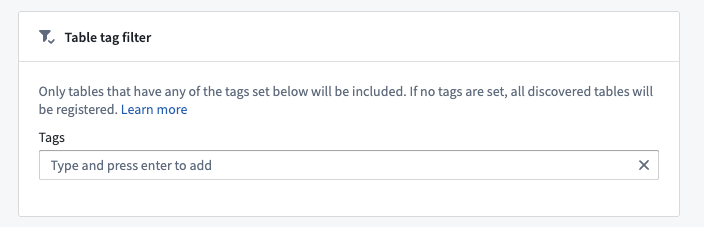
Tag filtering for Databricks sources
When configuring auto-registration for Databricks sources, you have the option of specifying a list of table tags to filter by. Only tables that have at least one of these tags set in the Databricks TABLE_TAGS ↗ system table will be registered.
Virtual tables in Code Repositories
When virtual tables are used in Code Repositories, the transforms consuming them will automatically obtain network egress based on the egress policies configured on the source. The credentials configured on the source will necessarily be made available to connect to the source. This is similar behavior to External Transforms.
The following settings must be enabled on the source:
- Code imports: This allows the source to be imported and used in a code repository. Further details of this setting and how to enable it can be found here.
- Export controls: This controls which security markings and organizations will be allowed on inputs to a Python Transform using a virtual table. Further details of this setting and how to enable it can be found here.
Once a source has been configured and imported into a code repository, virtual tables can be used as inputs to Python Transforms in the same way a dataset would be used, using transforms.api.Input. Incremental computation has a consistent API to that of datasets and is supported by a subset of sources. Refer to the source-specific documentation for more information.
In general, virtual tables are supported as inputs to Python, SQL, and Java Transforms. Only Python Transforms support creating a new virtual table as a transform output, while SQL and Java Transforms support writing to existing virtual tables.
Learn more about creating new virtual tables via Python Transforms.
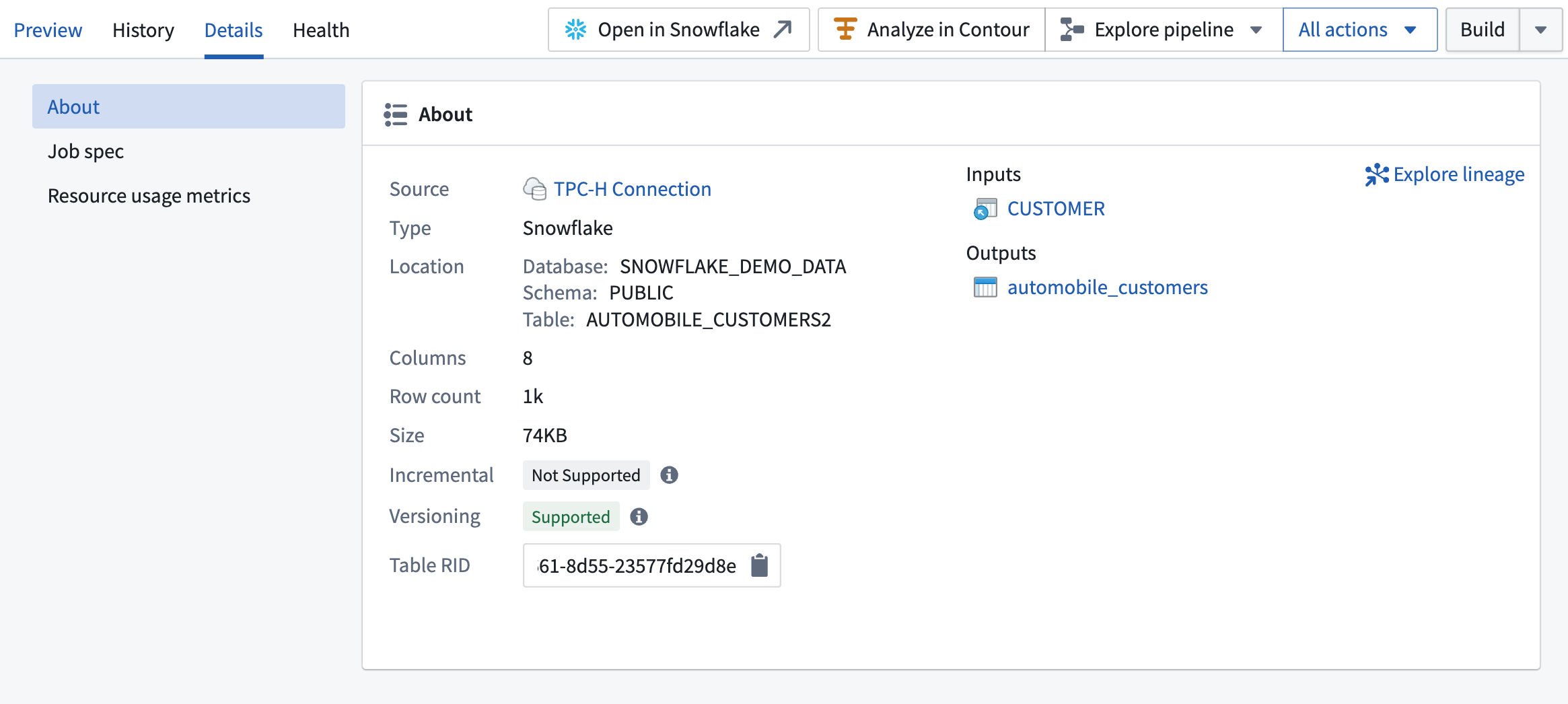
Viewing virtual table details
You can access key information about virtual tables in the Details panel of Dataset preview.
This includes:
- Incremental: If supported, you can configure incremental pipelines with the table, so downstream builds process only new or changed data instead of reprocessing all rows.
- Versioning: If supported, the table provides versioning, allowing Foundry to detect updates and skip unnecessary downstream builds when the data has not changed.
Update detection for virtual table inputs
The update detection feature monitors virtual tables and detects changes to the table in the source system. This allows you to use virtual tables as build triggers for dependent resources, such as pipelines or objects.
Update detection is only available if your virtual table input has been used to create downstream resources, such as downstream tables, datasets, or objects.
Update detection is intended for virtual table inputs, which are tables managed externally and registered in Foundry. Update detection is not necessary for virtual table outputs (created by Foundry pipelines), as Foundry automatically tracks updates for these using pipeline build information.
When update detection is enabled, Foundry regularly polls the source system to check for updates to the table. If the source table format supports versioning (for example, Delta or Iceberg), Foundry can detect changes and only trigger downstream builds when necessary. If versioning is not supported, every poll is treated as a potential update, which may result in unnecessary downstream builds.
You can check whether your virtual table supports versioning by viewing virtual table details.
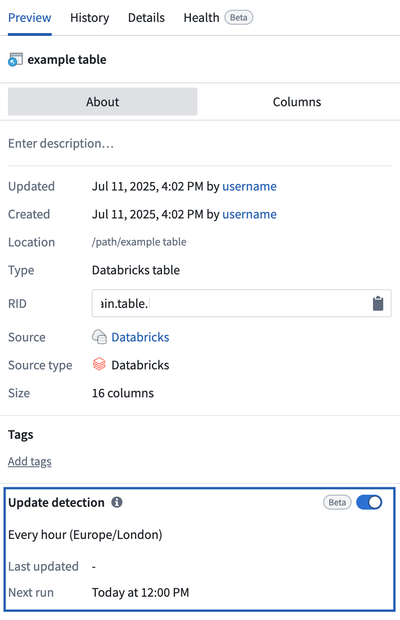
Enable update detection
To enable update detection for a virtual table input, follow these instructions:
- Open the virtual table in Dataset preview.
- Go to the update detection section in the left panel.
- Enable Update detection and set the desired polling schedule (for example, hourly or daily).
Once enabled, you can use the virtual table input as a schedule trigger for downstream tables and datasets. Any objects backed by the virtual table will reindex automatically when source updates are detected.
Configure objects backed by virtual tables
You can configure objects backed directly by virtual tables in Ontology Manager.
If the backing virtual table is updated outside of Foundry, you should enable update detection on the virtual table to ensure the objects receive regular updates from the source system.
Using virtual tables vs syncing to datasets
The decision to use virtual tables vs. sync to Foundry datasets depends on your architecture goals and the target workflow to be supported. We recommend considering the appropriate integration pattern on a workflow-by-workflow basis. The two approaches can be used in conjunction to complement one another.
Below are some considerations to keep in mind about the potential benefits, drawbacks, and limitations of using virtual tables vs. syncing data to datasets.
Benefits of using virtual tables
Virtual tables provide a number of benefits, including:
- Reduction of duplicate storage by not storing source data in Foundry. Note that Foundry will still store data for any downstream-created resources, such as datasets and objects that are outputs from Foundry pipelines.
- Queries can be pushed down to the source system to limit total data transfer. Note that availability of compute pushdown varies by source system and query type.
- Virtual tables may be especially beneficial for very large tables where duplicative storage costs become material.
- With virtual tables, data is queried directly upon use, without the need to synchronize data or consider potential for data staleness.
- Virtual tables provide optionality to help align Foundry implementation with target architecture patterns.
Drawbacks of using virtual tables
Virtual tables may not be the best choice in all circumstances. Some considerations include:
- Interactive performance may be slower than working with data stored in Foundry datasets.
- Compute usage may increase depending on the types of queries being run on the virtual table. For example, tables that are used as an input into a scheduled pipeline may generate limited compute compared to tables that are frequently accessed interactively in Contour analyses.
- Virtual tables do not benefit from Foundry dataset capabilities such as dataset versioning or branching.
Limitations of using virtual tables
Limitations of virtual tables include:
- Virtual tables are not available for all sources.
- Virtual tables require a Foundry worker source and direct egress policies.
- Connections using agent proxy policies are not supported.
- Connections using an agent worker are not supported.
- Not all Foundry applications and features support using virtual tables as inputs. However, any materialized resources created downstream of virtual tables, such as datasets and object outputs from pipelines, are fully supported across the Foundry ecosystem as usual.
- Transforms that use the
use_external_systemsdecorator are currently not compatible with Virtual Tables. Switch to source-based external_transforms or split your transform into multiple transforms, one that uses Virtual Tables as input and one that uses theuse_external_systemsdecorator.
Compute for queries on virtual tables
For queries run directly on virtual tables, compute may be split between Foundry and the source system. The specific behavior depends on the query and the degree of pushdown computation supported by the source system. Refer to the source-specific documentation for more information.