- Capabilities
- Getting started
- Architecture center
- Platform updates
Transactions
Foundry's Iceberg catalog extends standard Iceberg with all-or-nothing transaction semantics. When a job performs multiple writes through Foundry's build system, all writes either succeed together or are fully discarded, matching the existing guarantee for Foundry catalog datasets. This page explains how Foundry's Iceberg transaction semantics work, how this compares to default Iceberg behavior, and what it means for writing pipelines.
The transaction guarantees described on this page apply only when running jobs through Foundry's build system. When writing to Foundry's Iceberg catalog from an external client, you will get standard Iceberg transaction behavior. See PyIceberg API documentation ↗ for details on how transactions work in that context.
Foundry Iceberg transaction semantics
When running a build in Foundry, Foundry provides all-or-nothing updates. Foundry automatically wraps all Iceberg table reads and writes in a single transaction. Users do not need to take any action to configure this; it is the default behavior for writing to Iceberg tables using Foundry's build system.
By comparison, standard Iceberg lacks multi-update transaction guarantees. Instead, it provides atomic updates: each update is applied individually. This is a deliberate design choice that enables optimistic concurrency, meaning multiple writers can work against the same table simultaneously. While this model works well for single-write transactions, it can pose correctness issues for pipelines that perform multiple writes in a single transaction, whether those updates are applied to one table or multiple. Foundry's all-or-nothing transaction model addresses this by coordinating commits across all writes in a job, so partial updates are never visible.
In particular, Foundry's transaction model provides the following guarantees:
- All-or-nothing commits: All table updates in a job are committed together. If the job fails at any point, no partial writes are visible to downstream consumers or other jobs. This matches the behavior of catalog dataset transactions.
- Repeatable reads: If a table is read more than once within a job, the same data is returned both times, even if the table was updated externally between reads. Your pipeline sees a stable, consistent view of its inputs for the duration of the job.
- Jobs see their own writes: Writes made within a job are immediately visible to subsequent reads within the same job. They remain invisible to all other jobs and external readers until the transaction commits.
- Multi-table snapshot isolation: Foundry captures a consistent snapshot of all input tables at the start of the transaction. This ensures that partial external updates to an input cannot be partially read mid-job, and that data provenance — which version of an input produced which version of an output — is recorded correctly.
Example: incremental join pipeline
To illustrate the difference with an example:
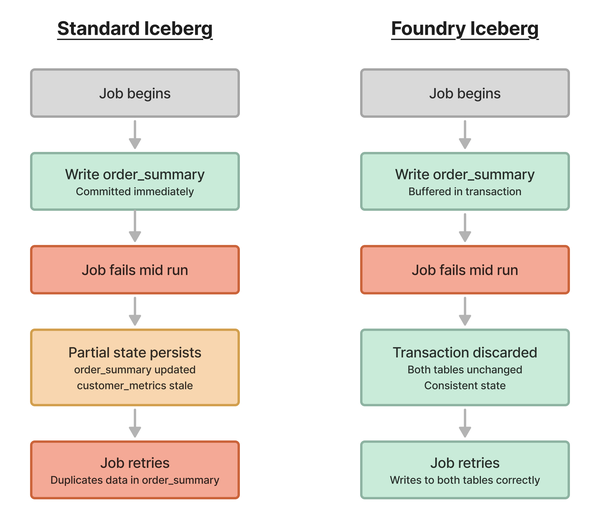
Assume you have a job that incrementally reads new rows from two tables called orders and customers, joins them, and appends results to two tables: order_summary and customer_metrics. One day the job fails mid-run, after processing the write to the first table (order_summary) but before writing to the second table (customer_metrics).
With standard Iceberg transaction semantics: the first write stands. The order_summary table would now reflect the new batch of data, while customer_metrics does not. The two outputs are in an inconsistent state. When the job is then retried, it re-reads the same input rows and writes them to order_summary again, duplicating data from the previous partial run.
With Foundry Iceberg transaction semantics: the first write is not committed. The order_summary table would not reflect the new batch of data. Both tables remain unchanged and in a consistent state. When the job is then retried, it writes the new data to both tables correctly without duplication.
Job queuing and optimistic concurrency
Foundry's build system ensures that at most one job runs against a given output at any point in time. Jobs writing to the same output are queued and run sequentially rather than concurrently. This means that in practice, write conflicts are not possible for regular pipeline jobs but can arise between pipeline jobs and Iceberg maintenance jobs.
By comparison, standard Iceberg uses optimistic concurrency, where multiple writers can work against the same table simultaneously, with conflicts detected and resolved at commit time. Foundry's transaction model trades away optimistic concurrency for a stricter approach to updates and correctness. If a transaction does encounter a conflicting concurrent update, the commit fails and the build system retries the job. Correctness is always preserved, at the cost of recomputing the job in case of conflicting updates.
A common source of conflicts is maintenance tasks such as compaction, which currently run concurrently to regular pipeline jobs. If a compaction task updates a table while a job is running, the job's transaction will fail to commit and the build system will retry the job. For tables that undergo frequent compaction, this can cause occasional retries.
Iceberg snapshot types and Foundry dataset transactions
If you are familiar with Foundry datasets, the transaction types you know map onto Iceberg snapshot types as follows:
| Iceberg snapshot type | Foundry dataset transaction | Description |
|---|---|---|
| Append snapshot | APPEND | Adds new data files; existing files are unchanged. |
| Overwrite snapshot | UPDATE, SNAPSHOT | Adds and removes data files, changing the logical set of records (including both partial and full overwrites). |
| Delete snapshot | DELETE | Removes data files or adds delete files to logically delete rows. |
| Replace snapshot | (no equivalent) | Rewrites data files without changing logical contents (e.g. compaction). |
A common point of confusion: the first write to a new Iceberg table is recorded as an append snapshot, even when the intent is to fully replace the table contents. This is expected. When a table is empty, appending data and replacing data are logically equivalent, as there is nothing to overwrite. Iceberg records the operation as an "append" because files were only added and none were removed. The practical implication is that if you see an append snapshot in a table's history for what you expected to be a full load, check whether it was the table's first write. On subsequent full rewrites to a non-empty table, the operation will correctly appear as an overwrite snapshot.