- Capabilities
- Getting started
- Architecture center
- Platform updates
Pipeline Builder tips and tricks
Whether you are building your first pipeline or refining a production workflow, the following tips help you work faster, stay organized, and get more out of Pipeline Builder. If you already have a pipeline set up, you can skip to Improve pipelines for tips on improving performance and reliability.
Build faster
Configure user preferences
- Navigate to the settings menu in the top right of the Pipeline Builder view and select User preferences, then configure and save your settings.
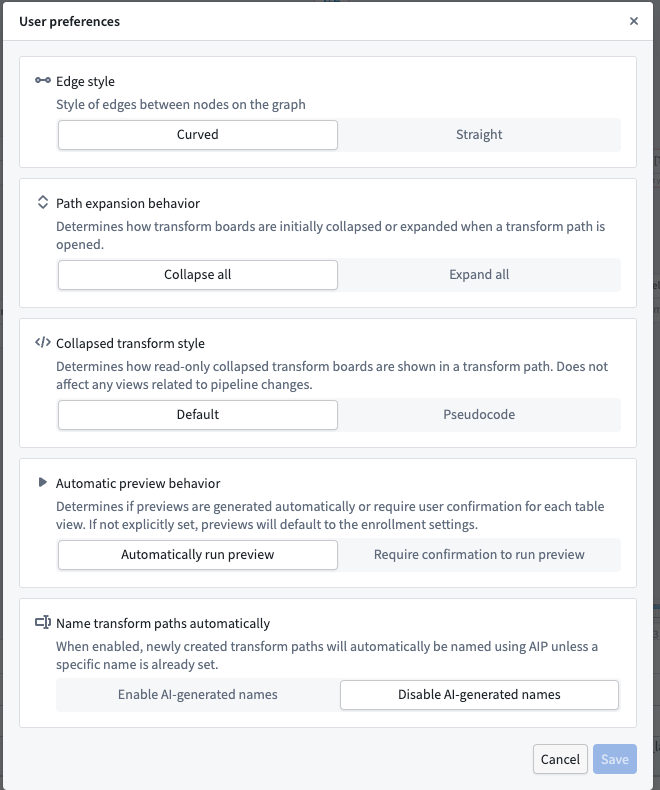
Two of the most commonly used settings are Collapsed transform style and Name transform paths automatically. Within the Collapsed transform style selector in User preferences, toggling the setting to Pseudocode renders your transforms in a format that resembles programming code. Pseudocode does not follow the syntax of any specific programming language.
Hotkeys (auto-layout, zoom, hide, and more)
- Open the Help dropdown menu in the top left of Pipeline Builder.
- Select View hotkeys to open the full hotkey reference for Pipeline Builder.
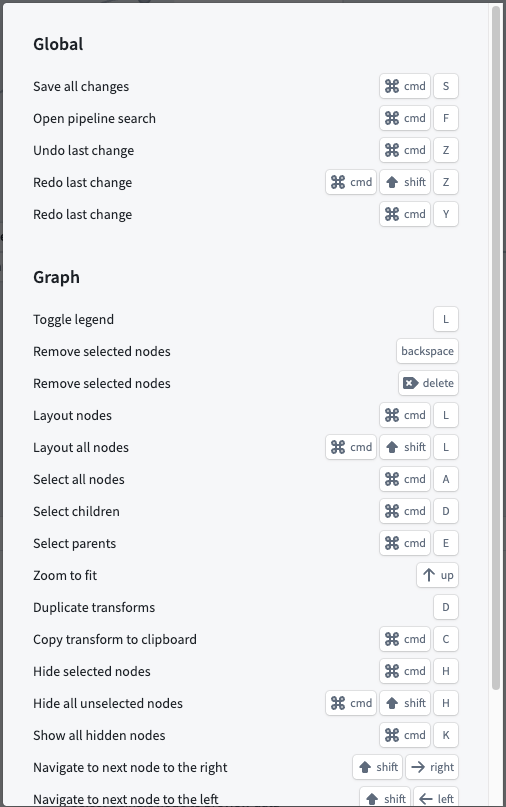
Some of the most commonly used hotkeys include:
Up Arrowto zoom and fit all pipeline nodes to the screenCmd+H(macOS) orCtrl+H(Windows) to hide selected nodesCmd+K(macOS) orCtrl+K(Windows) to unhide all hidden nodesCmd+D(macOS) orCtrl+D(Windows) to select children of a nodeCmd+E(macOS) orCtrl+E(Windows) to select parents of a nodeCmd+C(macOS) orCtrl+C(Windows) to copy nodes to the clipboard
Copy and paste nodes
- Select the nodes you want to copy. Use the Select button in the top right, or use
Cmd+A(macOS) orCtrl+A(Windows) to select all nodes in the current pipeline. If required, you can also select individual nodes, or select groups of nodes by selecting and dragging around them. - Copy your selection by right-clicking and choosing Copy, or use
Cmd+C(macOS) orCtrl+C(Windows).
- Navigate to the destination pipeline and paste by right-clicking and choosing Paste, or use
Cmd+V(macOS) orCtrl+V(Windows).
Click and drag to connect nodes
- Select the output circle of the node to use as input.
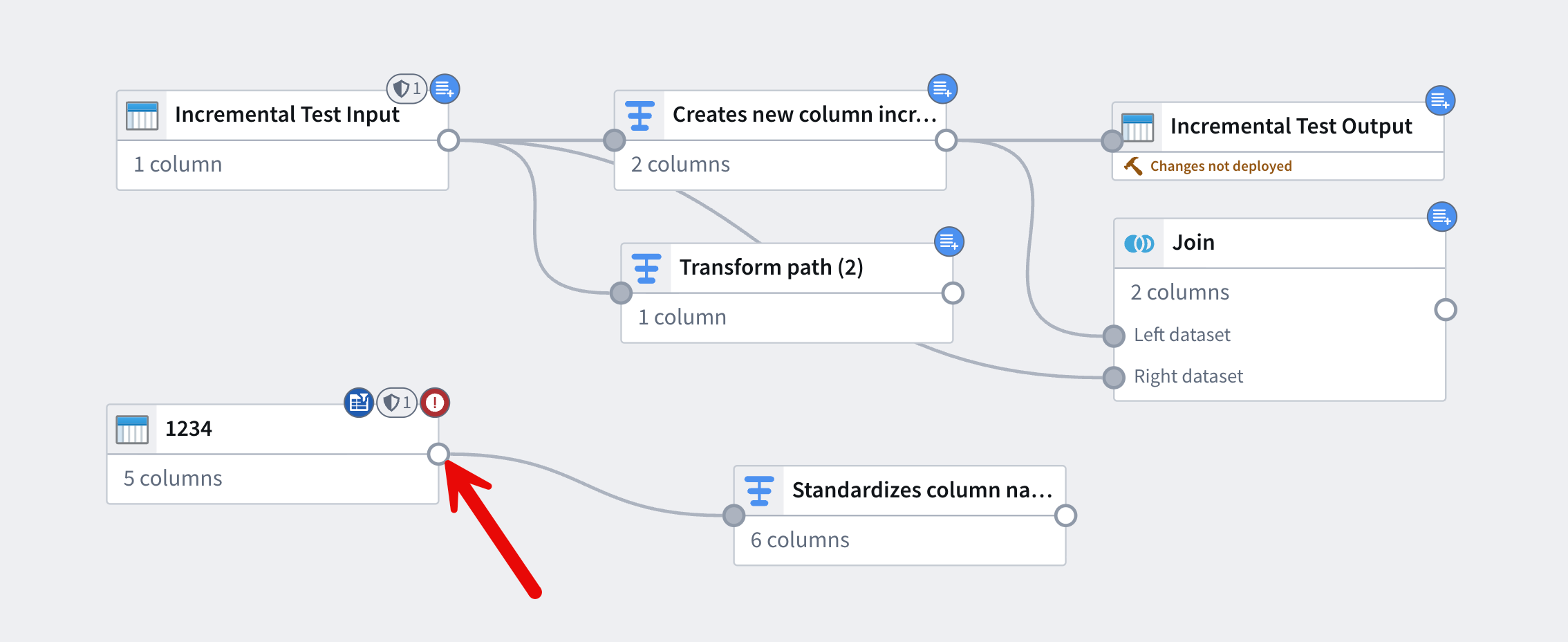
- Drag that output to the input circles of the nodes that should receive its output.
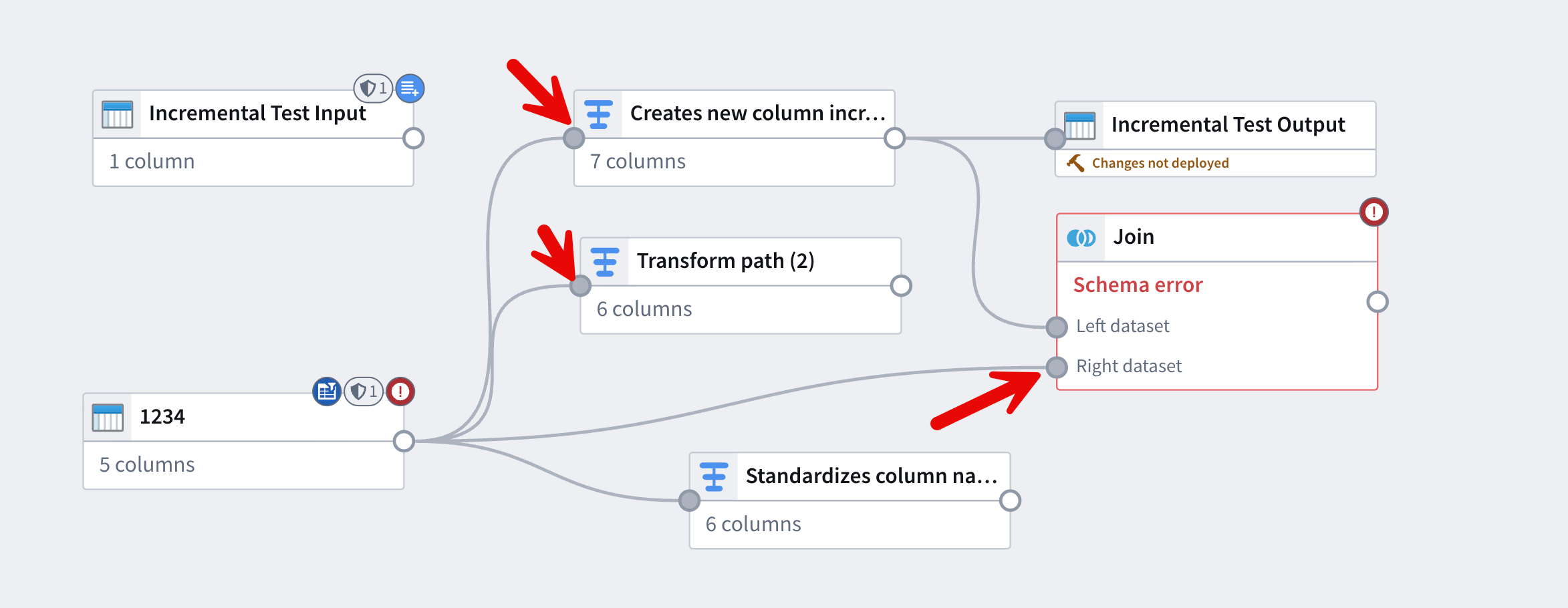
View unsaved changes
- Navigate to the sidebar menu on the right-hand side of your screen and select View changes. From here, you can view unsaved changes in your current branch and compare them with other Pipeline Builder branches.
Decide how many transforms to put per node
- There is no fixed limit on the number of transforms per node. As a general best practice, string larger transform functions together across multiple nodes rather than grouping everything into a single node. This makes your pipeline easier to maintain, troubleshoot, and update.
- Pipeline Builder also supports custom functions, which allow you to package a series of transform boards into a single reusable transform and reuse it throughout the pipeline. Select the + icon when in a transform node to configure a custom transform path.
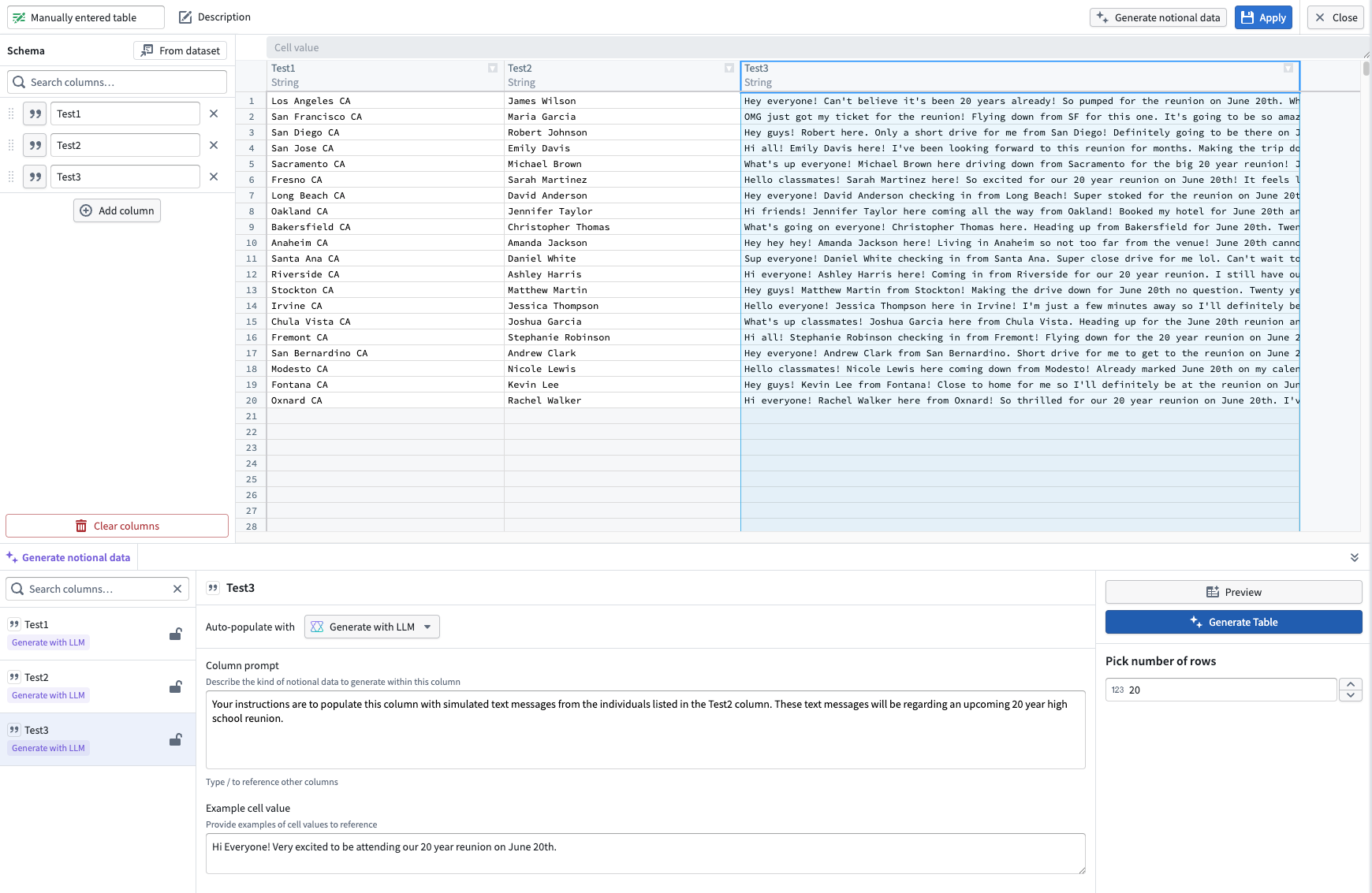
Generate notional data with LLMs
- After you add columns to your manually entered table, select Generate data from the top right.
- For each column, use the Auto-populate with dropdown to choose a data type, or select Generate with LLM to enter a custom prompt.
- Once your prompts are configured, select Generate table in the bottom right to populate the table.
AI tools for building and understanding
To use large language models (LLMs) directly in your pipeline, see Use LLMs in Pipeline Builder.
Use AI generate to build new transform nodes
- Select the node you want to build from and select Generate from the menu.
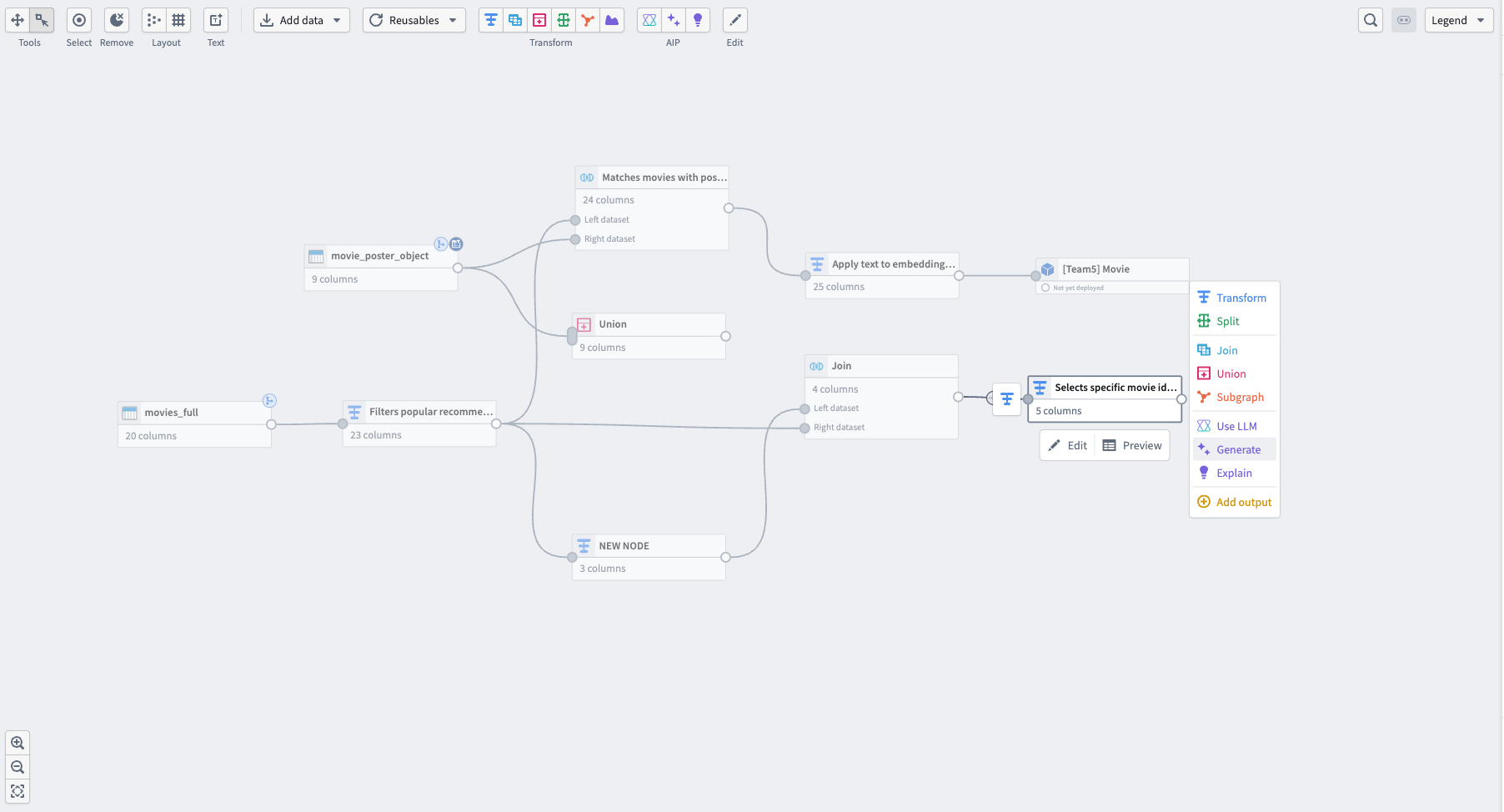
- Next, enter your prompt in the text box and select Generate.
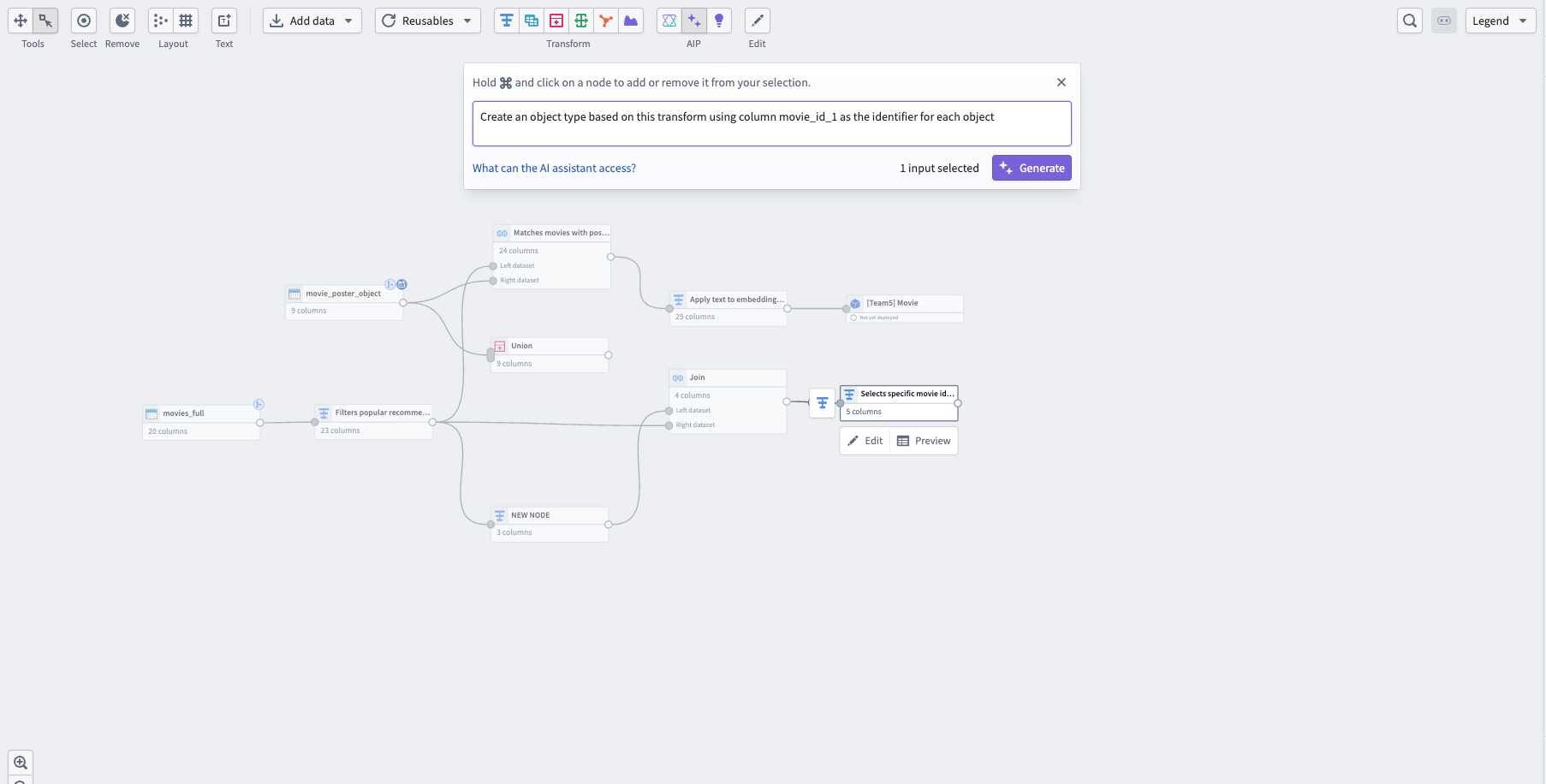
- Pipeline Builder generates the new node after the selected node, and you can rename it like any other node in your pipeline.
Use AI explain to generate a summary of your pipeline logic
- Select the nodes you want to explain and select the purple light bulb icon in the top center of the graph view. Pipeline Builder generates a written summary of the selected nodes' logic in the text box.
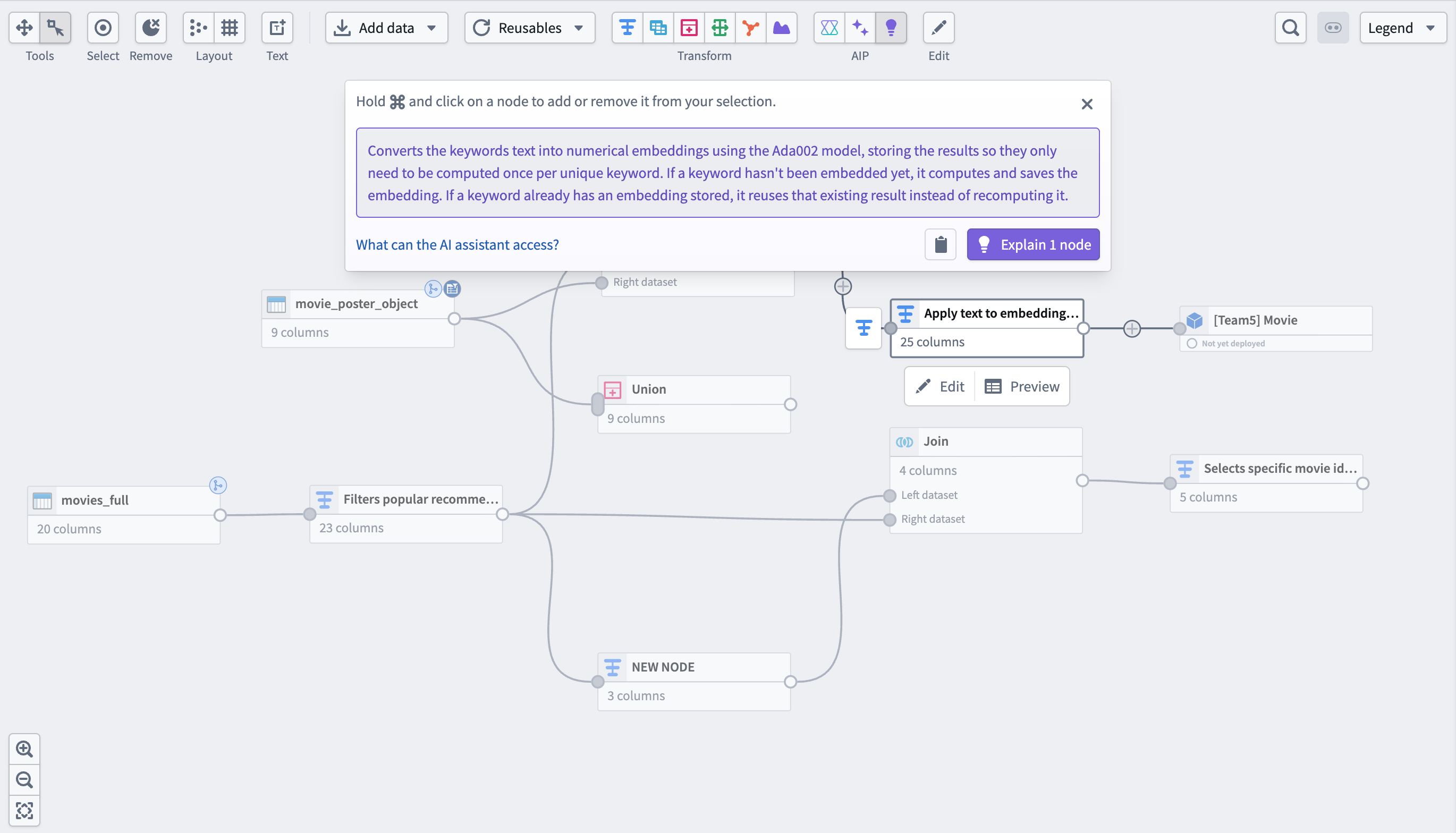
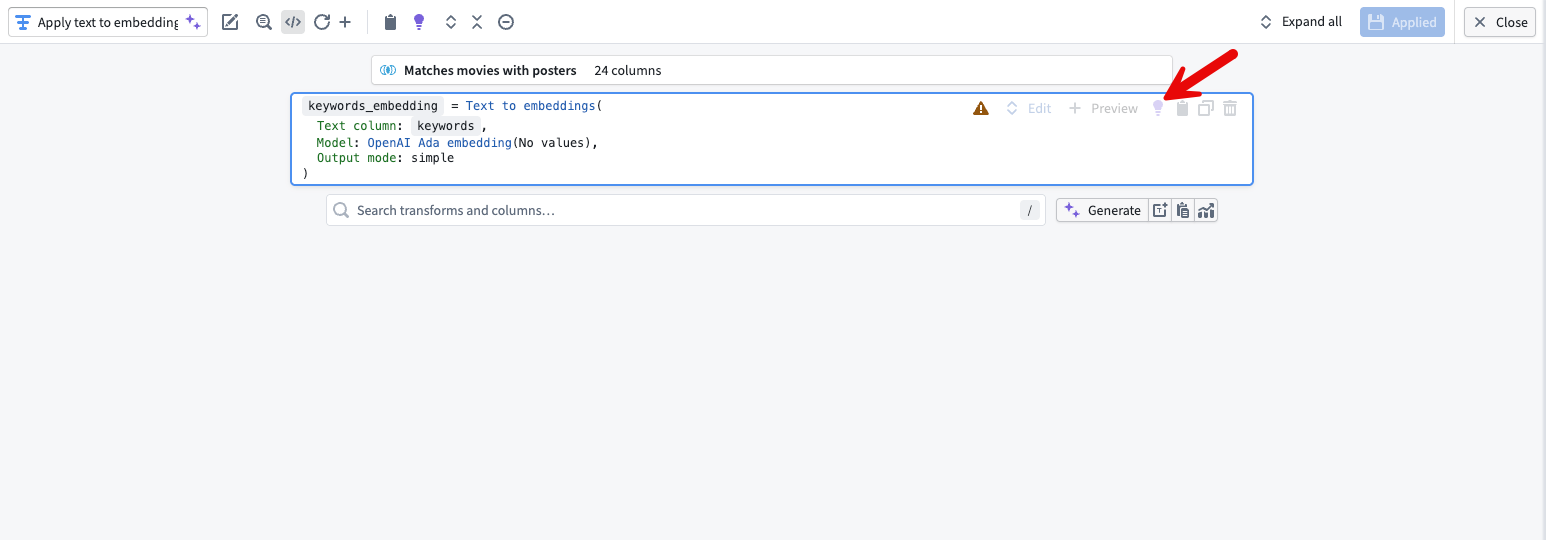
- You can also use explain directly in the node by selecting the purple light bulb in the top right of a transform board.
Use the AIP regex helper to generate regex patterns with an LLM
- Select the dataset you want to run a regex function on, then open the Transforms panel.
- In the Transforms window, select the regex function you need and the target column.
- Select the purple star icon to the right of the pattern input box and enter your prompt.
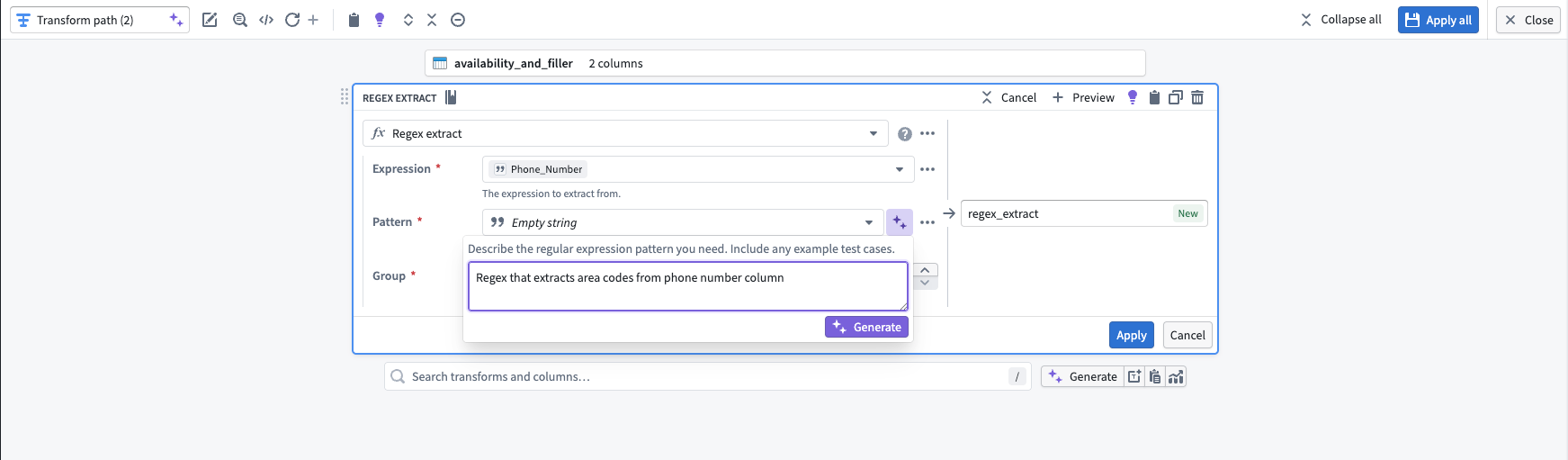
- Select Generate, then verify the output by selecting Apply. Return to the graph view and preview the transform's output to confirm the result.
Use AI FDE to support pipeline creation and building
- Navigate to the Applications menu on the left of your screen and search for AI FDE.
- Once you open the AI FDE application, you can add your existing pipeline as a resource by copying and pasting the link into the chat box.
- From there, you can prompt AI FDE to build additional nodes in your pipeline.
Improve pipelines
Faster pipeline mode
- When creating a new batch pipeline, select Faster from the Select batch compute menu.
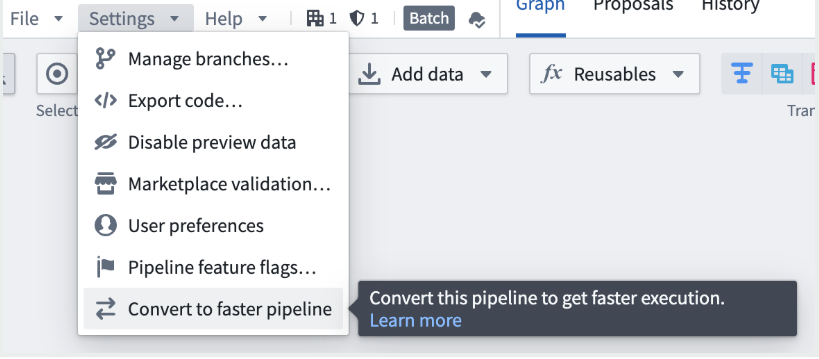
- You can also convert an existing standard batch pipeline to a faster pipeline. Select the Convert to faster pipeline option from the Settings menu in your standard pipeline.
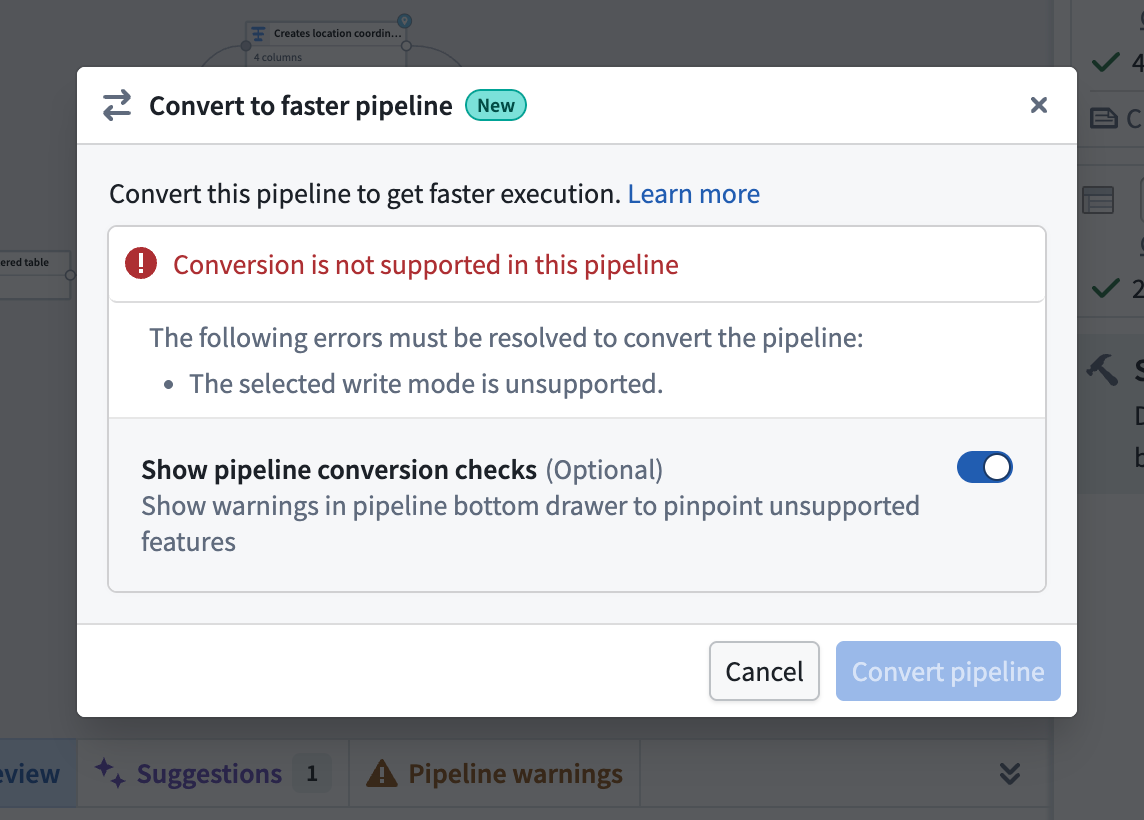
- Once you have selected the Convert to faster pipeline option, select the Convert pipeline button to confirm the conversion.
If your pipeline contains functionality that is not compatible with faster pipelines, you will receive an error message indicating what to remove or change before converting. You can also turn on conversion checks to view these warnings in your pipeline using the bottom panel.
Faster pipelines support a subset of the functionality available in standard batch pipelines. Learn more about faster pipelines with Pipeline Builder.
Compute profiles to reduce build times
- Once your pipeline is created, navigate to the Build settings menu on the far right of your screen to further adjust compute settings.
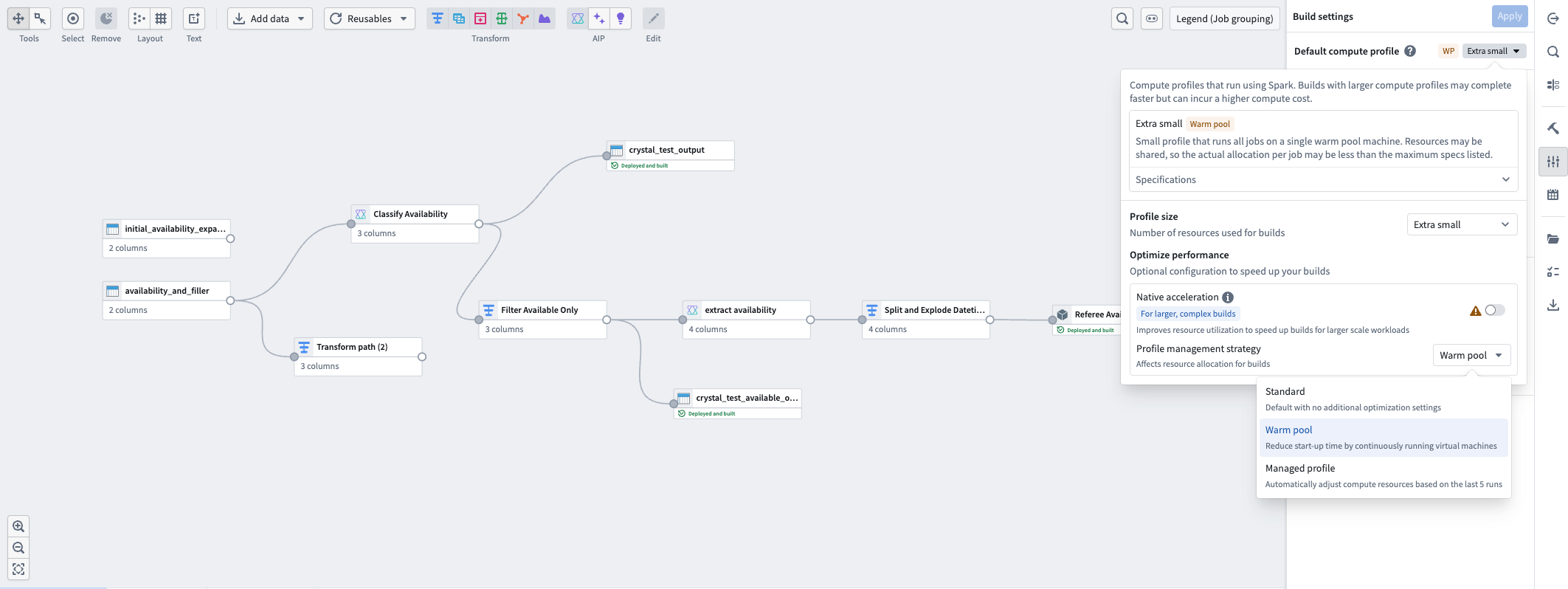
- In the Build settings menu, go to Default compute profile and select the dropdown showing your current compute profile size.
- Select the Profile management strategy dropdown. Three options are available. Select the one that best fits your needs:
- Standard: The default compute profile setting with no additional optimizations. Best for production-scale pipelines with predictable data volumes.
- Warm pool: Continuously runs virtual machines to reduce pipeline startup time. Best for small-scale, iterative pipelines and low-latency development tasks.
- Managed profile: Automatically adjusts compute resource allocation based on the last five runs of your pipeline. Best for pipelines with fluctuating data sizes or a need for compute cost management.
Faster pipelines only support the Standard profile management strategy.
Filter preview data
- Right-click the input dataset to sample from and select Sampling strategies from the dropdown menu. The sampling strategy you configure applies to every node that follows the sampled input.
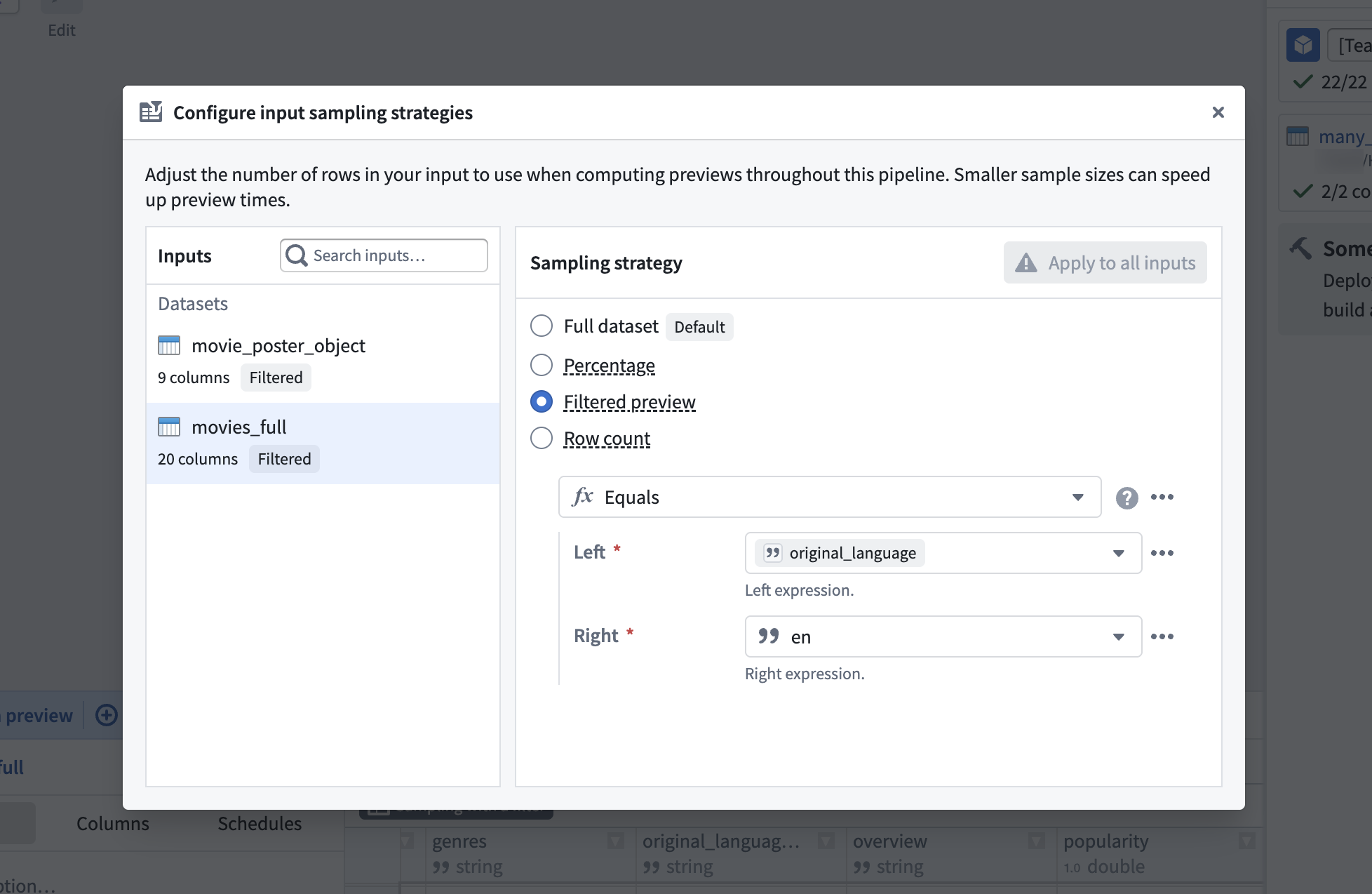
- Select which dataset in your pipeline to configure your sampling strategy on. Filtered preview allows you to filter rows based on any expression. In the following example, only rows where
original_languageisenare kept.
Unit tests for pipeline reliability
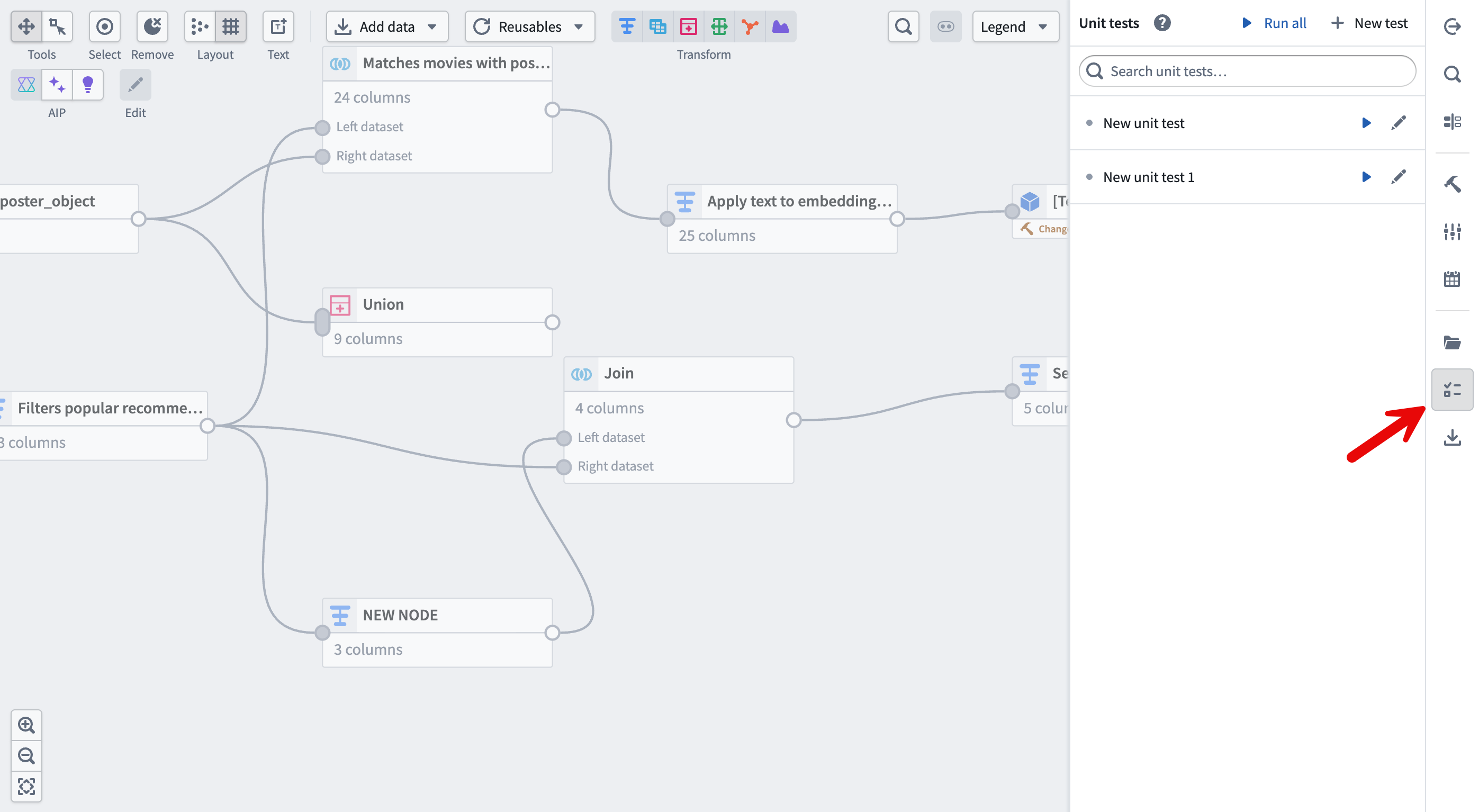
- Create a new unit test by selecting the icon on the right-hand side menu, selecting the + New test button, and selecting the transform you want to test.
- Next, configure your test by choosing a schema (manually or from an existing dataset), entering a line of test data in your Unit test input node, and entering the expected output in the Unit test output node.
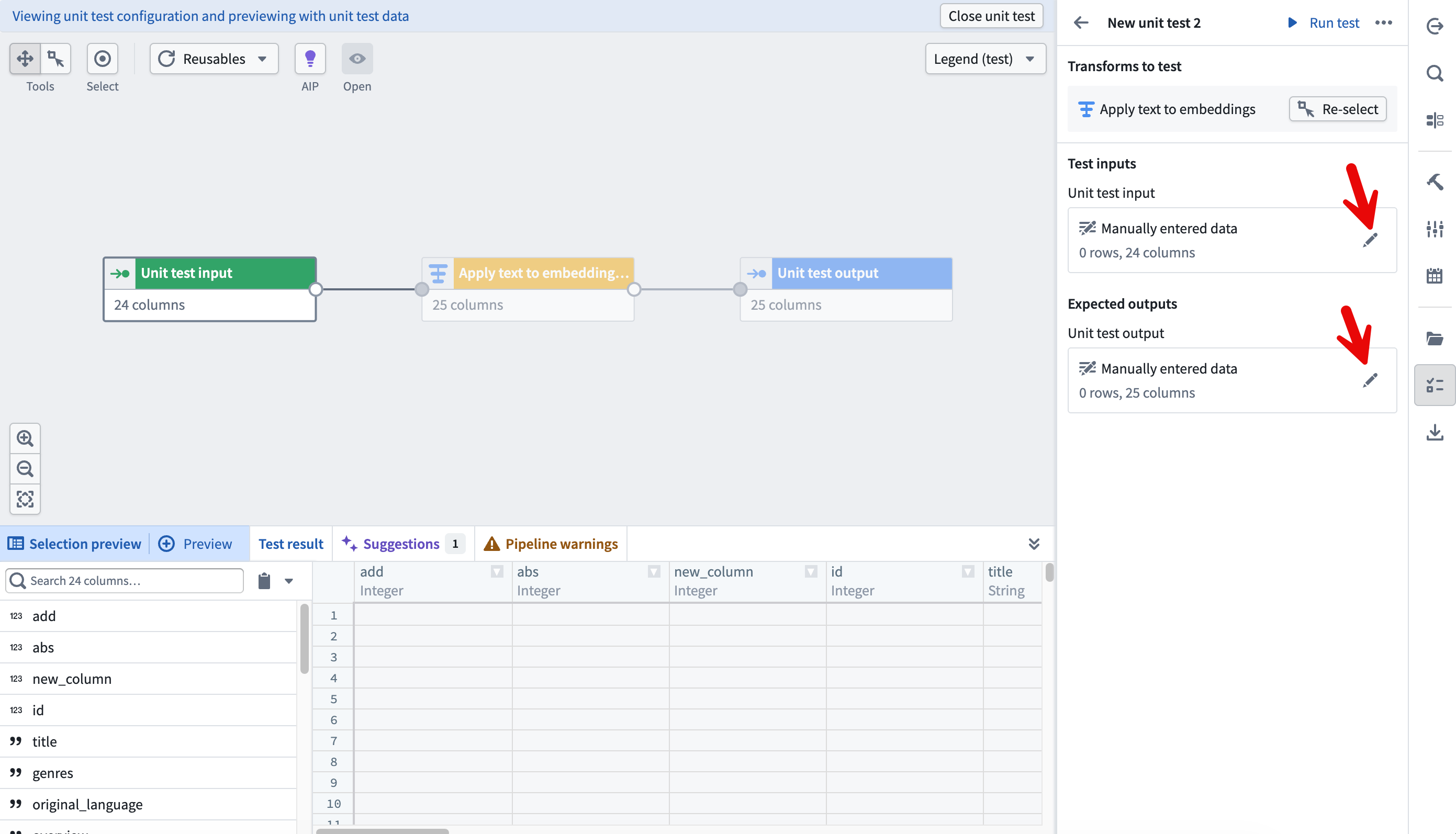
- Once your test is configured, select Run test and view the results. For more information, see Unit testing in Pipeline Builder.
Organize clearly
Folders and color groups for organization
- To set up folders for your nodes in Pipeline Builder, select the file icon on the far right of the screen. In the Pipeline file tree panel, you can create new folders, place nodes into folders, and show or hide nodes in specific folders.
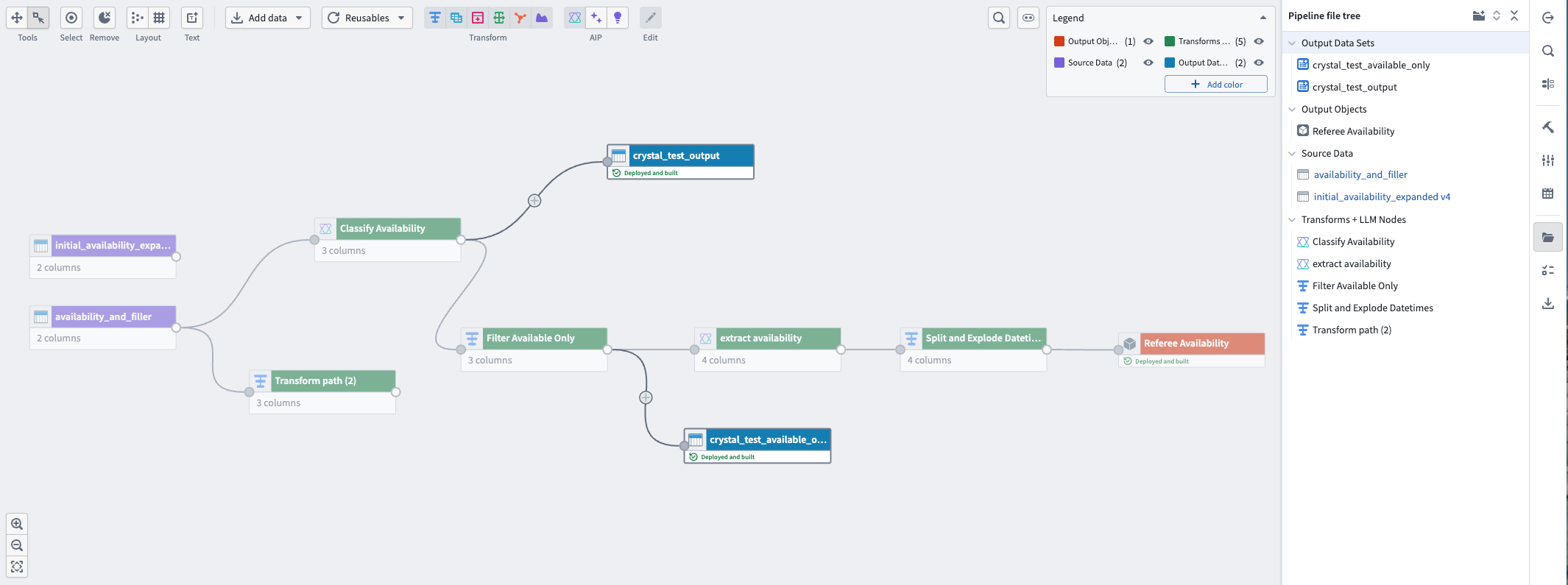
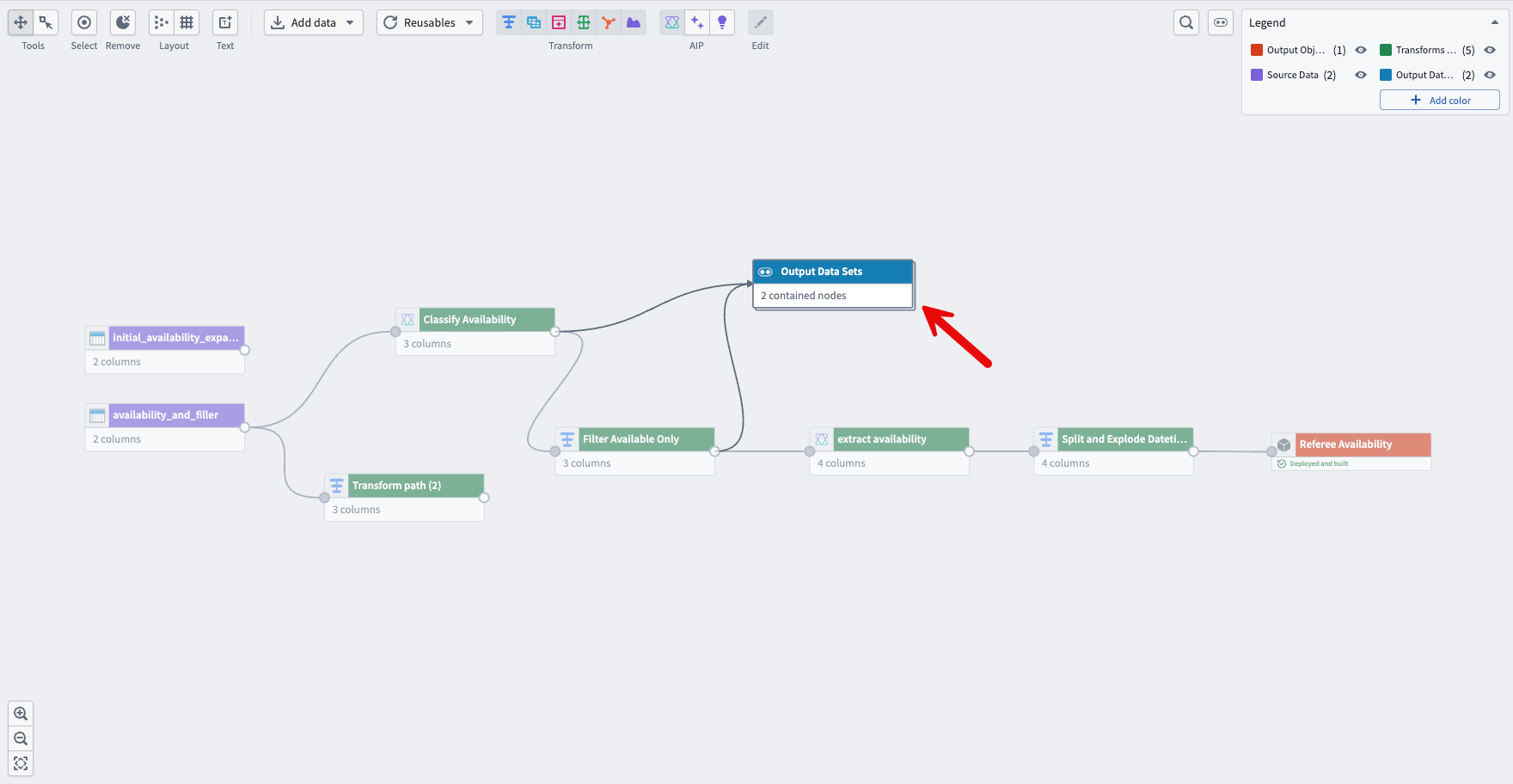
- You can also color nodes and collapse multiple nodes into a single node based on the coloring.
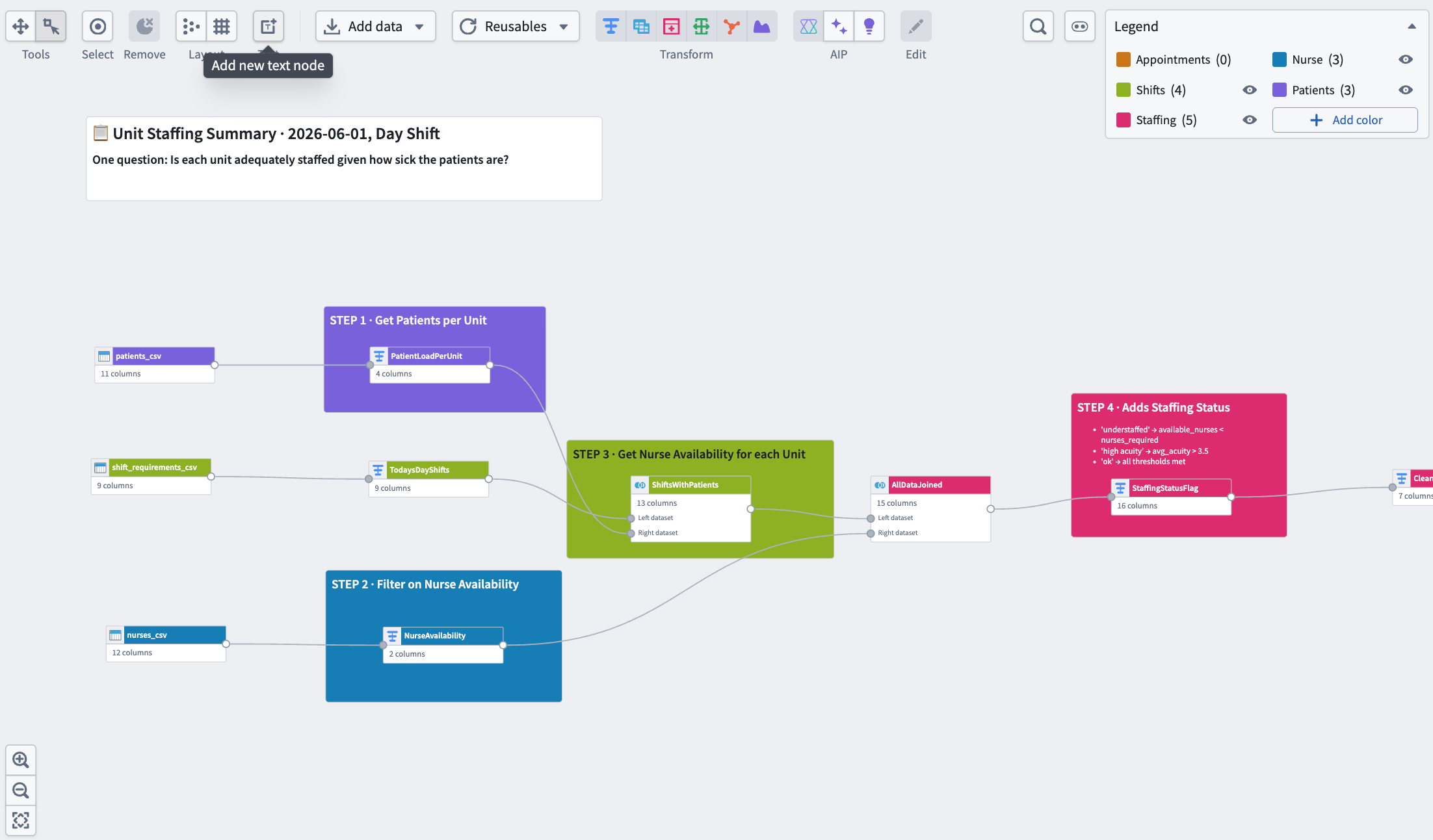
Text nodes for documentation
- Select Add new text node from the graph view toolbar. Text nodes support Markdown and are positioned behind any nodes in your graph. Learn more about text nodes.
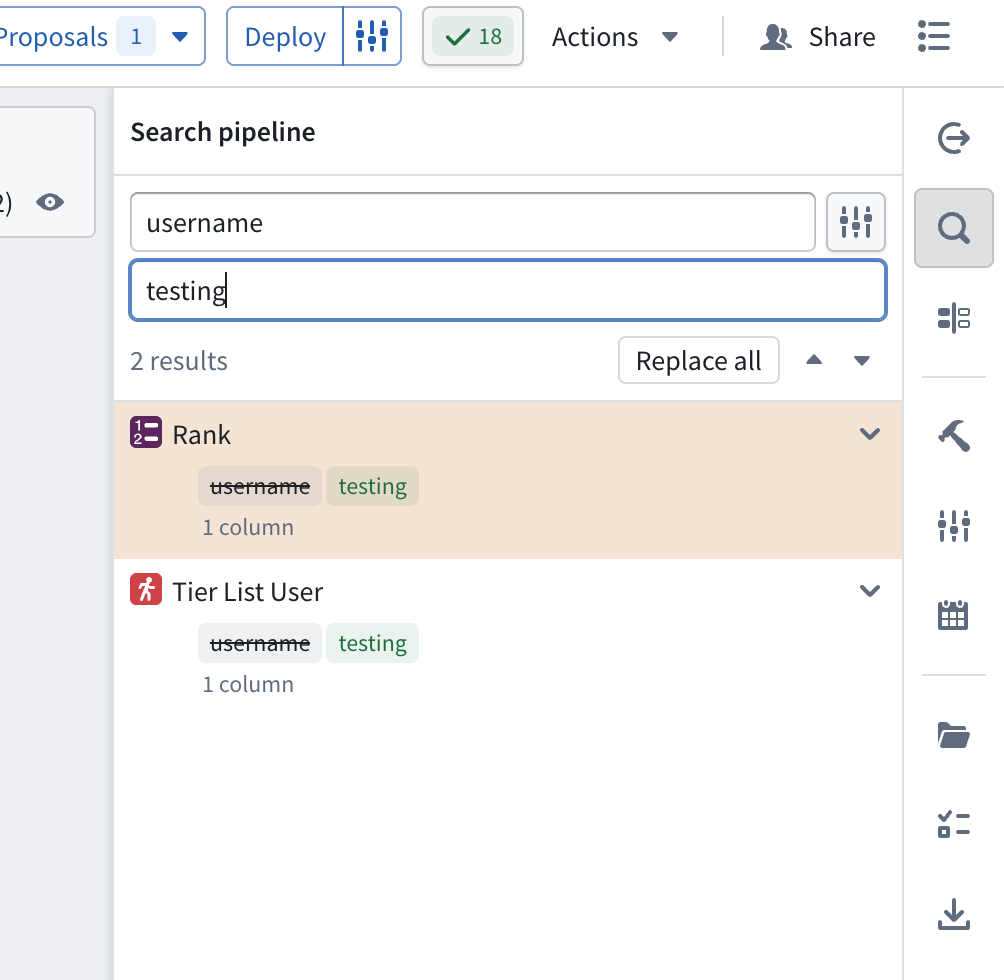
Find and replace column names
- Navigate to the search panel on the right-hand side of your screen. From there, you can search for and replace column names in your pipeline.
Auto-layout nodes and grid snapping
Use the automatic layout and grid snapping options from the graph view toolbar to align your nodes and improve readability.
