注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
Contour の非決定性
非決定的ウィンドウ関数
ROW_NUMBER、FIRST、LAST、LEAD、LAG、NTILE、ARRAY_AGG、または ARRAY_AGG_DISTINCT をウィンドウ関数で使用する場合、非決定性に注意してください。列 A でパーティションを分け、列 B で順序を付けているとします。同じ列 A の値に対して、列 B に同じ値を持つ複数の行が存在する場合、これらのウィンドウ関数の結果は非決定的であり、同じ入力データとロジックを与えても異なる結果を生成することがあります。
これらの式を expression board で使用する場合、ウィンドウ関数内の ORDER BY 句が決定的であることを確認するための警告が表示されます。
データを使用した例を見てみましょう:
| name | class | grade |
|---|---|---|
| Aaron | Math | 95 |
| Burt | Math | 95 |
| Chrissy | Math | 80 |
| Angelica | Science | 77 |
| Burt | Science | 81 |
| Charlie | Science | 66 |
各クラスで成績順に学生をランク付けしたいので、rank という新しい列を追加し、式 ROW_NUMBER() OVER (PARTITION BY "class" ORDER BY "grade" DESC) を使用します。
このような結果が得られます:
| name | class | grade | rank |
|---|---|---|---|
| Aaron | Math | 95 | 1 |
| Burt | Math | 95 | 2 |
| Chrissy | Math | 80 | 3 |
| Angelica | Science | 77 | 2 |
| Burt | Science | 81 | 1 |
| Charlie | Science | 66 | 3 |
しかし、時々このような結果も得られます:
| name | class | grade | rank |
|---|---|---|---|
| Aaron | Math | 95 | 2 |
| Burt | Math | 95 | 1 |
| Chrissy | Math | 80 | 3 |
| Angelica | Science | 77 | 2 |
| Burt | Science | 81 | 1 |
| Charlie | Science | 66 | 3 |
Aaron と Burt が Math で同じ成績を持っているため、rank 列は非決定的です。列を決定的にするために、name 列を式の order by 句に追加できます:ROW_NUMBER() OVER (PARTITION BY "class" ORDER BY "grade" DESC, "name" ASC)。この式では、同じ成績を持つ行のタイブレークに name 列を使用するため、常に以下の結果が得られます:
| name | class | grade | rank |
|---|---|---|---|
| Aaron | Math | 95 | 1 |
| Burt | Math | 95 | 2 |
| Chrissy | Math | 80 | 3 |
| Angelica | Science | 77 | 2 |
| Burt | Science | 81 | 1 |
| Charlie | Science | 66 | 3 |
その他の非決定的関数
上記のウィンドウ関数以外にも、CURRENT_DATE、CURRENT_TIMESTAMP、CURRENT_UNIX_TIMESTAMP、および MONOTONICALLY_INCREASING_ID も非決定的です。
CURRENT_DATE、CURRENT_TIMESTAMP、および CURRENT_UNIX_TIMESTAMP の場合、これらの値はパスの更新時にのみ計算されます。たとえば、1 日目に CURRENT_DATE で新しい列を作成し、2 日目にその分析に戻ると、新しい列には前日の日付が反映されます。
double 列の集計
Spark の計算が分散されているため、算術演算のオペランドの順序は非決定的です(つまり、1+2 と 2+1)。この非決定的な順序は、入力タイプ double を使用した場合に非決定的な出力を生成する集計をもたらすことがあります。つまり、double に対する集計は、同じ入力にもかかわらず、計算ごとに異なる結果を生成することがあります。これらの違いは非常に小さく、たとえば 0.000001 のようなものです。
たとえば、double 列の mean または variance を取ると、非決定的な列が生成されます。非決定的な列に対してアクション(たとえば、フィルター処理)を実行した場合、その結果も非決定的になります。
ユーザーの分析で double 列の mean、sum、stddev、variance、corr、または sum_distinct を取ると、非決定的な列が生成されます。
例を見てみましょう:
double 列 pickup_latitude があるとします。ピボットテーブルでは、double 列 pickup_latitude の平均を取っています。ピボットデータに切り替えると、非決定的な列が作成されます。
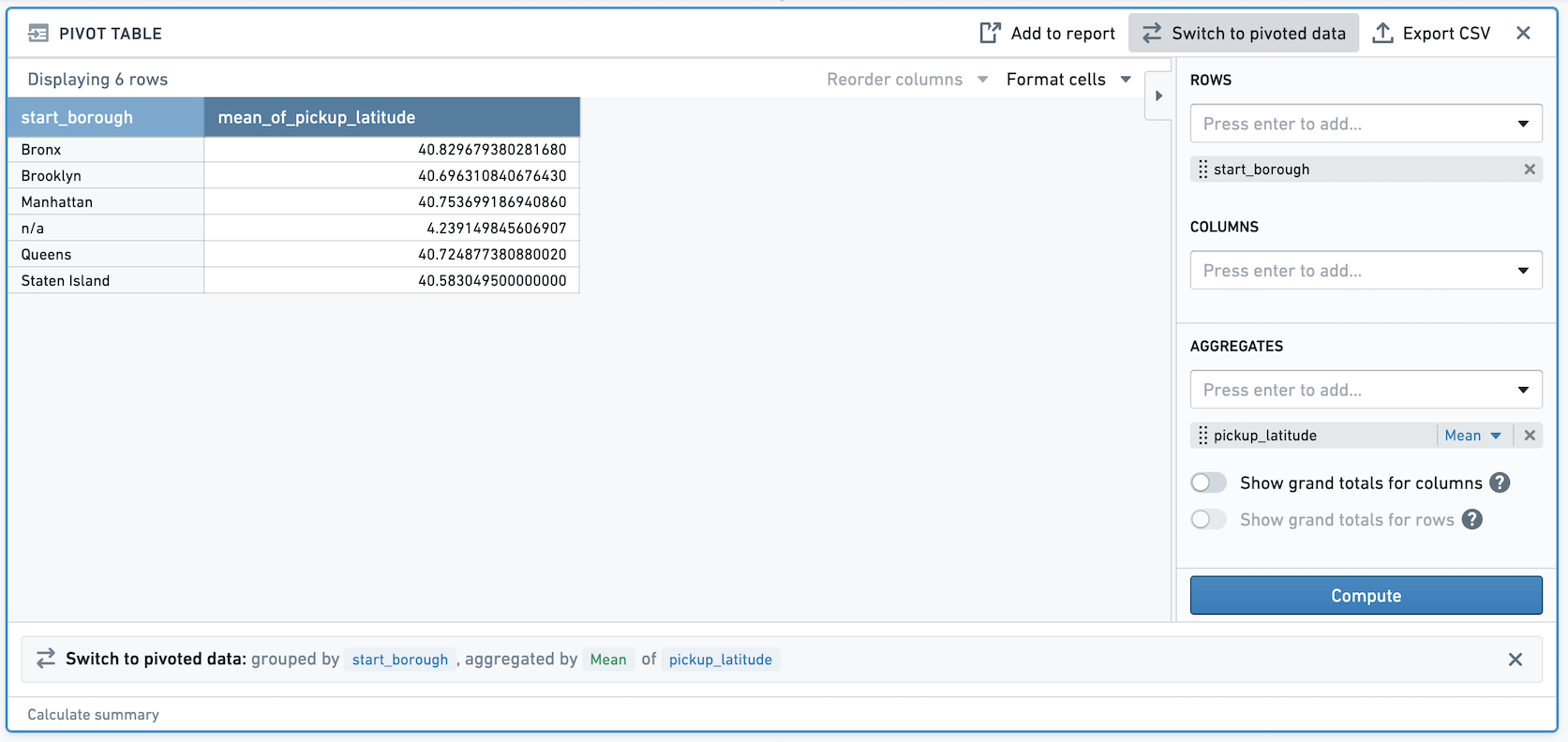
その後、新しく作成された列にフィルター処理すると、このフィルターの結果は非決定的になります。たとえば、上記のスクリーンショットでは、Staten Island の平均 pickup_latitude は 40.5830495 です。その値にフィルター処理すると、1 行が残ります。
ただし、このパスを再計算すると、平均の値がわずかに変わったために、フィルター後にその行が表示されなくなる可能性があります。非決定的な列に対して正確なフィルターの使用(たとえば、平均 = 40.5830495 へのフィルター処理)は避けることをお勧めします。また、非決定的な列を結合キーとして使用することも避けることをお勧めします。
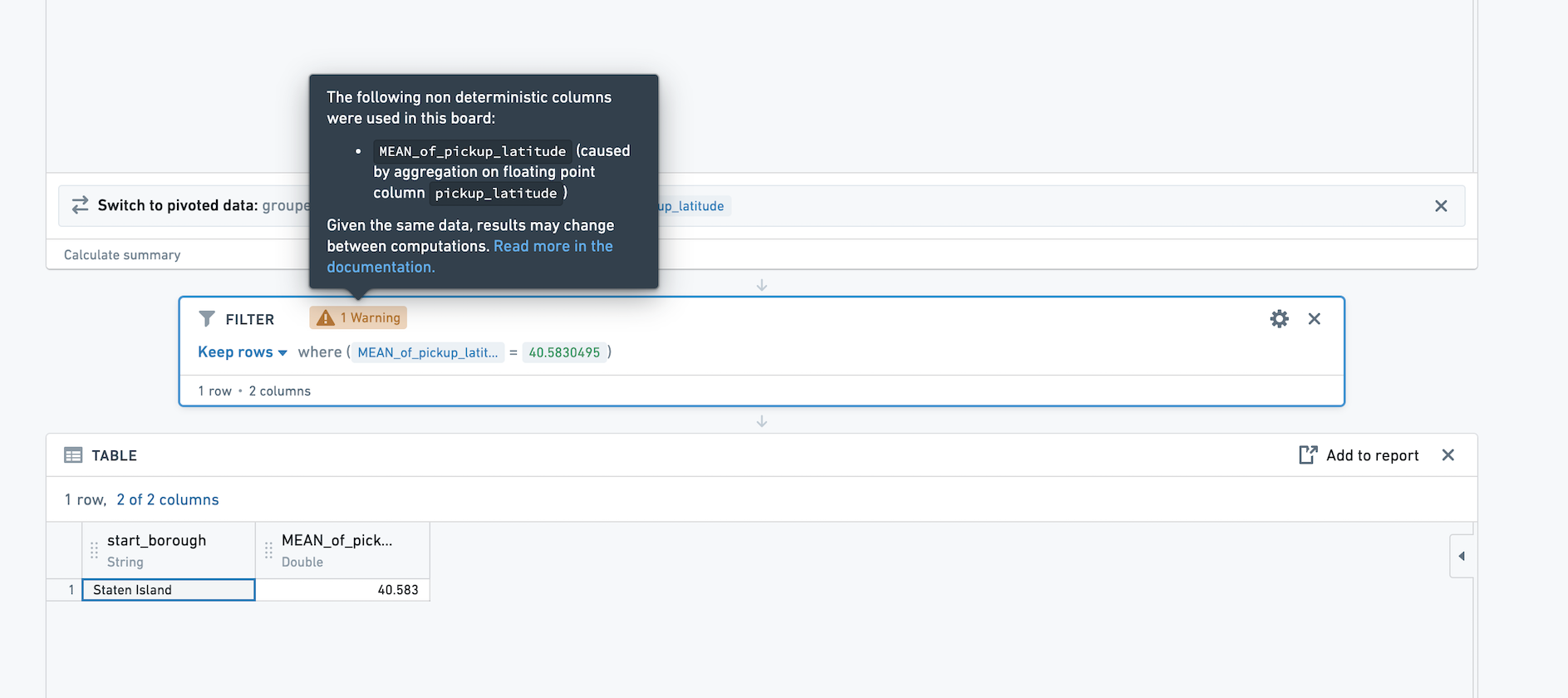
Contour で非決定的な列に対してアクションを実行する場合(たとえば、その列にフィルター処理する場合)、アクションが実行されるボードに警告が表示されます。警告には、非決定的な列の元となる集計が記載されています。
非決定性の診断
分析が非決定的である兆候の 1 つは、行数の不一致です。たとえば、Summary board を挿入し、行数が変わらない一連のトランスフォームを実行し、もう 1 つの Summary board を追加したとします。2 つの Summary board の行数が一致しない場合、上記のパスに非決定的な操作があるかどうかを調査する必要があります。UI で非決定的な関数を使用している場合や、double の集計を使用している場合に警告サインに注意してください。